
In today’s digital world, recommendation systems play a crucial role in personalizing user experiences. From e-commerce platforms suggesting products to users to streaming services recommending movies, these systems enhance user engagement by predicting relevant items. One of the most effective architectures for large-scale recommendation tasks is the Two-Tower Recommender System.
In this article, we will explore the fundamental principles of the Two-Tower Recommender System, understand its key components, and dive deep into its internal mechanisms, including embeddings, neural networks, and the role of the dot product in matching users with items.
The Foundation of Two-Tower Models: Embeddings and Neural Networks
The Two-Tower Recommender System is built upon two essential machine-learning concepts:
Embeddings:
An embedding is a dense vector representation of categorical data, such as users and items.
Instead of treating users and items as discrete entities, embeddings map them into a continuous space where similar entities have similar representations.
Word embeddings (like Word2Vec, FastText, or GloVe) are widely used in NLP, but in recommender systems, embeddings help in learning relationships between users and items.
Neural Networks:
The Two-Tower model uses neural networks to process and transform embeddings.
These networks learn complex relationships between users and items by mapping high-dimensional sparse input data into dense vector representations.
Understanding Word Embeddings in Recommender Systems
Word embeddings, initially developed for natural language processing, have found applications in recommendation systems. Instead of words, recommendation systems use embeddings for users and items. For example: In an e-commerce platform, a user embedding might encode their purchase history, browsing behavior, and demographics. An item embedding might capture product category, brand, price range, and user reviews. By learning these embeddings, the system can identify similar users and items, improving recommendation quality.
User Tower and Item Tower: The Core of the Model
The Two-Tower model consists of two main components: a user tower and an item tower. Both towers are neural networks designed to process and transform raw input features into dense embeddings.
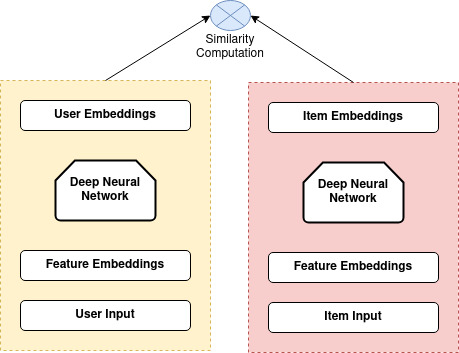
The User Tower
Processes user-related information (e.g., user ID, past interactions, demographics, preferences).
Transforms raw user data into a dense user embedding.
Uses a neural network with multiple layers to learn user representations.
Example input features:
User ID (Categorical, converted to embedding)
Past purchases (List of item embeddings)
Age, location, or gender (Numerical features)
The Item Tower
Processes item-related information (e.g., item ID, category, textual descriptions, ratings).
Converts raw item data into a dense item embedding.
Uses a neural network similar to the user tower to learn item representations.
Example input features:
Item ID (Categorical, converted to embedding)
Product category, brand (Categorical, one-hot encoded or embedded)
Price, rating (Numerical features)
The final output of each tower is a vector representing the user and the item, respectively. The interaction between these vectors is often calculated as the dot product or cosine similarity which determines the estimated interest of the user in the item. When recommending items to users, we first represent both users and items as numerical vectors (embeddings). These embeddings help us either find relevant items for a user (retrieval) or rank them based on how much the user might like them (ranking). The way these two sets of embeddings interact is called fusion, and there are two main types:
Late Fusion (Good for Fast Retrieval):
The user and item embeddings are calculated separately and later compared using a similarity measure (like cosine similarity).
Since item embeddings are pre-computed and stored, the system can quickly retrieve the most similar ones for a given user.
This method is great when speed is important, such as when quickly fetching recommendations from a large catalog.
Early Fusion (Good for Precise Ranking):
User and item features are merged early in the process, allowing the model to analyze their interactions more deeply.
This approach is more complex and computationally heavy because it needs to dynamically compute relationships for each user-item pair.
It is best suited for ranking tasks where accuracy is more important than speed, ensuring that the top results are highly relevant.
Role of the Dot Product in Matching Users and Items
Once the user and item embeddings are obtained, the similarity between them is computed using a dot product. This operation measures how closely the two embeddings align in the vector space. In terms of mathematical representation, if U represents the user embedding and I represents the item embedding, the similarity score is computed as:
Score = U * I
Where * denotes the dot product operation.
A higher score indicates a stronger match between the user and item, leading to a higher likelihood of recommendation.
Example of Dot Product in Action
If we have:
User embedding U = [0.1, 0.2, 0.3]
Item embedding I = [0.4, 0.5, 0.6]
The dot product will be: 0.1 * 0.4 + 0.2 * 0.5 + 0.3 * 0.6 = 0.04 + 0.1 + 0.18 = 0.32
This similarity score helps rank items for recommendations.
Training a Two-Tower Model
Before training a recommendation model, we need to define positive and negative samples:
Positive Samples: Items a user interacted with (e.g., clicked ads, purchased products).
Negative Samples: Items a user did NOT interact with, which can come from:
Items never retrieved.
Items retrieved but later discarded.
Items shown to the user but ignored.
The choice of negative samples affects how well the model learns to distinguish between relevant and irrelevant items.
Comparison of Training Methods:

Applications of the Two-Tower Recommender System Across Various Industries
The Two-Tower Recommender System is a powerful machine learning model widely used in recommendation-based applications. Here’s how it benefits various industries:
1. E-commerce: Personalized Product Recommendations
In e-commerce platforms, personalized recommendations are key to enhancing the shopping experience. The Two-Tower model processes customer preferences and product attributes separately, then computes similarity scores to suggest relevant products. This improves:
- Product discovery based on past interactions.
- Upselling and cross-selling opportunities.
- Customer engagement and retention.
2. Streaming & Media: Enhancing Content Discovery
Streaming services like Netflix, YouTube, and Spotify rely on recommendation engines to personalize content for users. The Two-Tower model helps by:
- Matching users with content based on watch history, genre preferences, and behavior.
- Offering dynamic recommendations that adapt to real-time user interactions.
- Improving content discovery, leading to longer user sessions and better retention.
3. Healthcare: Personalized Treatment and Drug Discovery
In healthcare, the Two-Tower model can recommend treatments and medications tailored to individual patients by analyzing:
- Electronic health records (EHRs) and patient histories.
- Similar cases and their treatment outcomes.
- Genetic and molecular data for personalized drug recommendations.
4. Finance & Banking: Fraud Detection and Investment Advice
Financial institutions leverage Two-Tower architectures for personalized banking solutions and fraud detection. Key applications include:
- Recommending financial products (credit cards, loans, investments) based on user spending patterns.
- Detecting anomalies in transactions to identify fraudulent activities.
- Providing automated financial planning and risk assessment.
5. Education & E-Learning: Personalized Course Recommendations
In e-learning platforms, the Two-Tower Recommender System helps improve student engagement by:
- Suggesting courses, tutorials, or learning materials based on past activities.
- Identifying knowledge gaps and recommending supplementary content.
- Enhancing adaptive learning experiences for personalized education.
To The Horizon:
Two-tower models provide a flexible and powerful framework for designing recommendation systems that balance speed and accuracy. By selecting the right fusion technique (late or early fusion) and training method (pointwise, pairwise, or listwise), developers can fine-tune these models for either efficient retrieval or highly accurate ranking, depending on the use case. For large-scale applications where speed is critical, late fusion with precomputed embeddings enables rapid item retrieval. Conversely, when precision matters most, early fusion allows deep user-item interaction modeling, leading to more personalized recommendations. Beyond traditional recommendation systems, two-tower models have proven effective in search engines, ad targeting, and content ranking, making them a cornerstone in machine learning-powered personalization. As technology advances, integrating them with multi-modal data (text, images, audio) and reinforcement learning could further enhance their capabilities, ensuring even more relevant and engaging user experiences. We build custom AI-powered recommendation systems tailored for your industry, ensuring improved customer engagement and business growth.