
Introduction
Recommender systems have become an essential component of digital platforms, personalizing user experiences across domains such as e-commerce, streaming services, and social networks. Among the various recommendation approaches, collaborative filtering (CF) has emerged as one of the most widely used techniques due to its ability to generate personalized recommendations without requiring explicit content information. Collaborative filtering relies on historical user interactions to infer preferences and suggest relevant items. This blog provides a comprehensive exploration of collaborative filtering-based recommender systems, covering fundamental concepts, mathematical formulations, advantages and challenges, and advanced techniques such as matrix factorization and deep learning.
Fundamentals of Collaborative Filtering
Collaborative filtering operates on the principle that users with similar past behaviours will likely have similar future preferences. The core component of a CF-based recommender system is the user-item interaction matrix, which represents user preferences in the form of explicit ratings (e.g., a user rating a movie on a scale of 1 to 5) or implicit interactions (e.g., clicks, purchases, or watch history). Given this partially filled matrix, the goal of CF is to predict the missing values and recommend items to users.
Collaborative filtering (CF) is a popular technique in recommendation systems that relies on past interactions to suggest relevant items to users. It operates under the assumption that users with similar behaviors or preferences are likely to have overlapping interests. Collaborative filtering can be broadly classified into two main types:
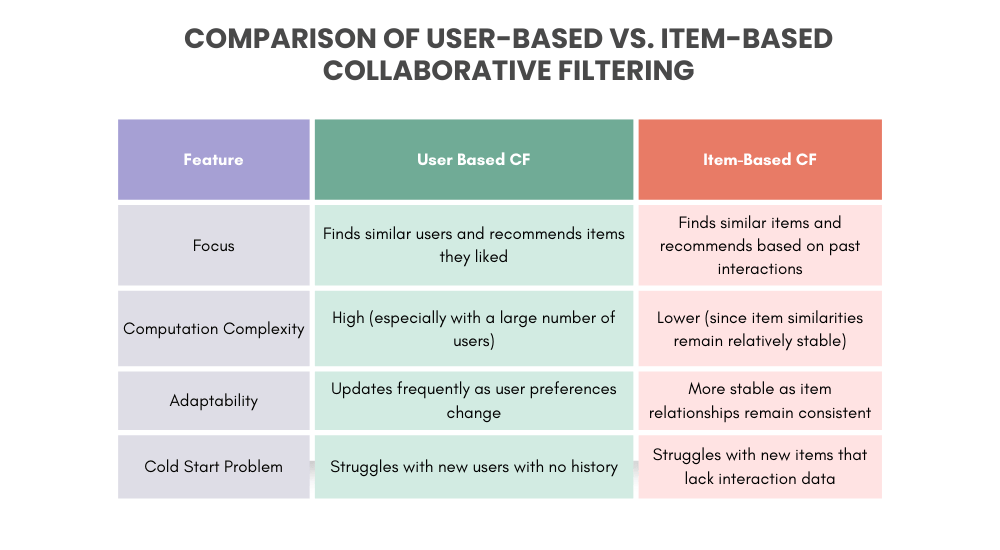
1. User-Based Collaborative Filtering (UBCF)
User-based collaborative filtering generates recommendations by identifying users who exhibit similar behavior patterns and preferences. It assumes that if two users have shown similar interests in the past, they are likely to have common interests in the future. The steps involved in this approach are:
User Similarity Calculation: The system computes a similarity score between users based on their historical interactions, typically using metrics like cosine similarity, Pearson correlation, or Jaccard similarity.
Neighbor Selection: A set of most similar users (nearest neighbors) is chosen based on the similarity scores.
Prediction and Recommendation: Items that the selected neighbors have interacted with but the target user has not are recommended. The recommendations are weighted based on the similarity of users and the rating or interaction strength of the items.
A potential drawback of user-based CF is that it can be computationally expensive, especially in large-scale systems, as user preferences frequently change and require recalculating similarities dynamically.
2. Item-Based Collaborative Filtering (IBCF)
Item-based collaborative filtering, instead of focusing on user relationships, examines the similarity between items. The core idea is that items that are frequently interacted with together (e.g., rated similarly or purchased together) share a strong relationship, and thus, a user who interacts with one item may be interested in similar items. The steps involved in this approach are:
Item Similarity Calculation: The system analyzes historical interactions to determine how similar two items are, using similarity metrics like cosine similarity, adjusted cosine similarity, or Pearson correlation.
Building an Item Similarity Matrix: A matrix is created where each item is mapped with similar items based on historical co-occurrences in user interactions.
Recommendation Generation: When a user interacts with or rates an item, the system recommends other similar items based on the similarity matrix.
Item-based CF is often preferred in large-scale recommendation systems since item relationships tend to remain more stable over time compared to user preferences, making it computationally more efficient.
Similarity Measures in Collaborative Filtering
A key aspect of collaborative filtering is the computation of similarity between users or items. Several similarity measures are commonly used in CF, each with its strengths and applicability depending on the nature of the data.
Cosine Similarity: Cosine similarity measures the angle between two vectors, capturing how similar two users or items are in terms of their interaction history. It is calculated as:

Pearson Correlation Coefficient: Pearson correlation adjusts for differences in rating scales across users by normalizing the data. It is defined as:
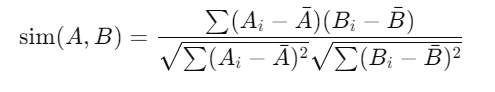
Jaccard Similarity: For binary interactions, such as whether a user has purchased an item, Jaccard similarity is useful. It measures the ratio of shared interactions to total interactions:
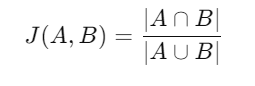
Prediction Mechanisms in Collaborative Filtering
Once similarity has been computed, the next step is to predict the missing ratings in the user-item matrix. In user-based collaborative filtering, a missing rating for a user is predicted based on the ratings of similar users:
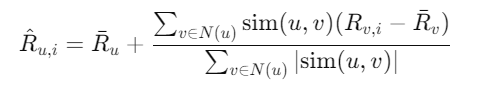
In item-based collaborative filtering, predictions are computed by aggregating ratings of similar items:
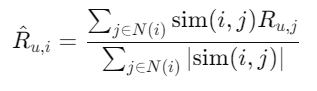
Step-by-Step Process of User-Based Collaborative Filtering
Data Collection: Construct a user-item interaction matrix with explicit ratings or implicit interactions.
Similarity Computation: Calculate similarity between users using cosine similarity, Pearson correlation, or Jaccard similarity.
Neighbour Selection: Identify the most similar users for the target user.
Rating Prediction: Predict missing ratings by aggregating ratings from similar users.
Recommendation Generation: Recommend top-N items with the highest predicted ratings.
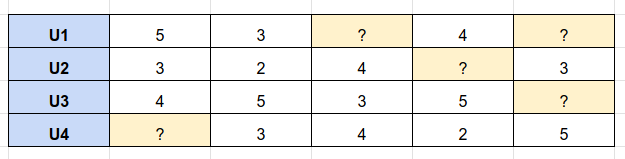
Using similarity measures, we estimate the missing ratings for U1 and recommend the highest-rated items.
Finding Top-N Recommendations for a User:
Compute similarity scores between the target user and all other users.
We compute the similarity between U1 and other users using cosine similarity or Pearson correlation. For simplicity, let's assume similarity scores:
Sim (U1, U2) = 0.9
Sim (U1, U3) = 0.8
Sim (U1, U4) = 0.7
Select the top-k similar users based on the similarity scores.
Assuming we take U2 and U3 as the top-2 similar users to U1.
Aggregate ratings from these similar users for the unrated items.
For User-Based CF, the missing rating for an item i for user u is predicted using



4. Rank the predicted ratings and recommend the top-N items with the highest scores.
Since Item C (4.5) > Item E (3.8), Item C is recommended first.
Step-by-Step Process of Item-Based Collaborative Filtering
Data Collection: Construct a user-item interaction matrix.
Item Similarity Computation: Compute item-item similarity using cosine similarity or Pearson correlation.
Weighted Rating Calculation: Compute predicted ratings based on user’s past interactions with similar items.
Recommendation Generation: Recommend top-N items with the highest predicted scores.
Instead of comparing users, we compare items and infer missing ratings based on similar items that users have already rated.
Finding Top-N Recommendations for a User:
Compute similarity scores between items based on user interactions.
Identify top-k most similar items for each item that the target user has rated.
Predict the missing ratings by aggregating ratings from similar items.
Rank the predicted ratings and recommend the top-N highest-rated items.
For example, assume the similarity between
Sim (Item C, Item A) = 0.9
Sim (Item C, Item D) = 0.7
Since U1 has rated Item A = 5 and Item D = 4, the predicted rating for Item C is computed using the weighted average:

Similarly, if Item E is similar to Item A (0.8) and Item D (0.6), then:
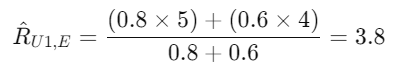
Since Item C (4.5) > Item E (3.8), Item C is recommended first.
Challenges in Collaborative Filtering
Despite its effectiveness, collaborative filtering suffers from several challenges.

Data Sparsity and User Overlap: CF algorithms require substantial user-item interactions, but in many real-world scenarios, the user-item matrix is sparse. Users often interact with only a small fraction of available items, making it difficult to generate accurate recommendations. For instance, a movie recommendation system may struggle to suggest an indie film if only a few users have rated it.
- Scalability: As the number of users and items increases, the computational complexity of CF methods grows significantly. This can result in longer processing times and higher operational costs, particularly for real-time recommendation systems. Large-scale platforms, such as e-commerce sites with millions of products, may face challenges in delivering instant recommendations.
Cold Start Problem: New users and items with little or no interaction history pose a major challenge. Without sufficient data, CF struggles to provide relevant recommendations. For example, a new user joining a music streaming service may initially receive generic recommendations until they have rated enough songs for the system to infer preferences.
Synonymy and Shilling Attacks: Recommender systems can struggle with synonymy, where different items serving the same purpose are treated as distinct due to variations in descriptions or titles. Additionally, shilling attacks—where malicious users manipulate ratings to either promote or demote specific items—can distort recommendations. For example, a competitor might artificially inflate ratings for their own products while degrading the reputation of rival products.
Lack of Diversity and Serendipity: CF-based systems often reinforce familiar recommendations, limiting diversity. Users may repeatedly receive suggestions for similar items, reducing opportunities for unexpected or novel discoveries. For instance, a book recommendation system might continuously suggest romance novels to a user who has shown interest in the genre, ignoring the possibility that they might also enjoy science fiction.
Privacy Concerns: Since collaborative filtering relies on user data, privacy remains a significant challenge. Users may hesitate to share their preferences, especially on platforms with inadequate data protection policies. A relevant example is a health-related recommendation system that analyzes sensitive user data to provide personalized suggestions, raising ethical and security concerns.
Advanced Techniques in Collaborative Filtering
To address these limitations, advanced methods such as matrix factorization and deep learning have been introduced.
Matrix Factorization (SVD, ALS):
Matrix factorization techniques decompose the user-item interaction matrix into lower-dimensional representations, allowing for better generalization and prediction of missing values. Singular Value Decomposition (SVD) and Alternating Least Squares (ALS) are commonly used approaches.
Deep Learning-Based Collaborative Filtering:
More recent advancements leverage deep learning models such as Neural Collaborative Filtering (NCF) and Autoencoders for CF. These models can capture complex non-linear relationships between users and items, improving recommendation accuracy. Additionally, Graph Neural Networks (GNNs) have been employed to incorporate knowledge graphs and social relationships into CF-based recommendations.
Conclusion
Collaborative filtering remains a foundational technique in recommender systems, powering personalized experiences across numerous industries. While traditional CF methods like user-based and item-based approaches are effective, challenges such as cold start and scalability necessitate advanced techniques like matrix factorization and deep learning. With the integration of graph-based methods and self-supervised learning, CF continues to evolve, offering even more accurate and efficient recommendations for the future.