
With technological advancement and economic growth, fraud in the financial industry has surged, costing institutions and consumers hundreds of billions annually. Fraudsters constantly evolve to exploit vulnerabilities, targeting areas like credit card transactions, insurance, money laundering, and securities trading. Traditional fraud prevention methods alone aren’t enough to curb these crimes. This makes fraud detection systems essential—not only to catch fraud after it happens but also to save on the massive potential losses involved.
Financial fraud—spanning credit card scams, insurance fraud, money laundering, healthcare fraud, and securities violations—has drawn significant attention from those aiming to curb it. The economic impact is concerning, with global losses running into billions each year, and estimates suggesting over $400 billion in yearly costs to the U.S. alone. The rapid rise in these crimes underscores the need for enhanced fraud prevention and detection efforts.
Anomaly Detection Techniques :
Anomaly detection through machine learning and artificial intelligence has a vast history and both supervised algorithms and unsupervised learning algorithms have been applied for the same. Some of the common algorithms are explained below :
A. Supervised Algorithms:
These algorithms use labeled historical datasets to train models that learn to make decisions and classify patterns. By learning from past examples, supervised algorithms can identify recurring patterns and determine whether new data points fit known categories, making them ideal for detecting known types of fraud. Here are some supervised algorithms.
Support Vector Mechanism (SVM): It is a non-parametric supervised learning technique and is suitable for binary classification problems of financial frauds. SVMs work by mapping the input space into a higher dimensional feature space to find an optimal separating hyperplane. They can achieve this without introducing any further computational complexity and are suitable for working with a high number of features.
Random Forest : This is an ensemble-based supervised learning technique well-suited for classification tasks, including fraud detection. A random forest operates by constructing multiple decision trees during training and making predictions based on the majority vote of the trees. Each tree in the forest is built from a random subset of features, allowing the model to capture diverse patterns and reduce overfitting. Random forests are efficient with high-dimensional data and can handle complex data structures, making them robust against noise and outliers in financial datasets.
Neural Network: Neural networks are powerful supervised learning models inspired by the human brain, making them effective for complex fraud detection tasks. They consist of interconnected layers of nodes (or "neurons") that process and learn intricate patterns in data. Neural networks excel in capturing non-linear relationships by learning hierarchies of features through multiple hidden layers. While they can require significant computational resources and a large amount of data to perform well, neural networks are highly adaptable and effective for detecting subtle anomalies, such as those found in fraudulent transactions.
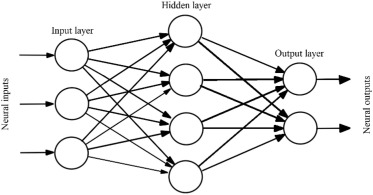
Source : https://ars.els-cdn.com/content/image/1-s2.0-S0957417421017164-gr3.jpg
B. Unsupervised Algorithms :
While supervised learning excels at learning from historical datasets to make predictions, unsupervised learning is valuable when encountering new, unusual cases. Unlike supervised methods, unsupervised learning doesn’t rely on labeled data, making it ideal for detecting unexpected patterns or anomalies that haven’t been seen before—such as emerging types of fraud. This flexibility allows unsupervised models to adapt and identify novel outliers in real time.
Here are some unsupervised algorithms.
Isolation Forest: Isolation Forest is an unsupervised anomaly detection algorithm specifically designed to identify outliers or anomalies. It works by isolating data points in a dataset through random partitioning. Anomalies, which are few and different, require fewer random splits to isolate compared to normal data points. This approach makes Isolation Forest efficient and scalable, even with large datasets. It’s particularly useful in fraud detection, as it can highlight unusual patterns without needing labeled data, making it effective for discovering unknown types of fraud.
Autoencoder (AE): An autoencoder is a type of unsupervised deep learning model characterized by its symmetric architecture, featuring fewer nodes in the middle layers. It consists of two main components: the encoder, which compresses the input data into a lower-dimensional representation, and the decoder, which reconstructs the original input from this encoding. The primary objective of training an autoencoder is to learn an efficient, reduced encoding of the data while maintaining the ability to accurately reconstruct it.
These are some of the major machine learning algorithms used for identifying financial fraud. Each algorithm has its own strengths and weaknesses, and the choice of which one to use depends on various factors, including the nature of the data, the number of features available, and the specific use case at hand. Understanding these nuances is crucial for effectively detecting and preventing fraudulent activities in the financial sector.