Introduction:
Imagine a world where different types of data—images, text, audio, depth, thermal, and motion (Inertial Measurement Unit - IMU)—could all understand and interact with each other seamlessly. That’s the vision behind IMAGEBIND, a groundbreaking approach developed by researchers at Meta AI. This innovative method creates a unified embedding space, enabling various modalities to align and work together without needing all possible combinations of paired data.
Major Insights:
Emergent Alignment: IMAGEBIND demonstrates that aligning each modality with images leads to an emergent alignment across all modalities, enabling innovative applications like zero-shot audio classification using text descriptions.
Performance: The approach achieves strong results on various benchmarks, often outperforming specialist models trained on specific modalities. For instance, it shows impressive performance on audio classification and retrieval tasks, even when not directly trained for these tasks.
Compositional Tasks: IMAGEBIND supports creative applications like combining audio and image embeddings to retrieve images that match both inputs. This ability to compose information from different modalities opens up new possibilities in multimedia applications.
Key Features:
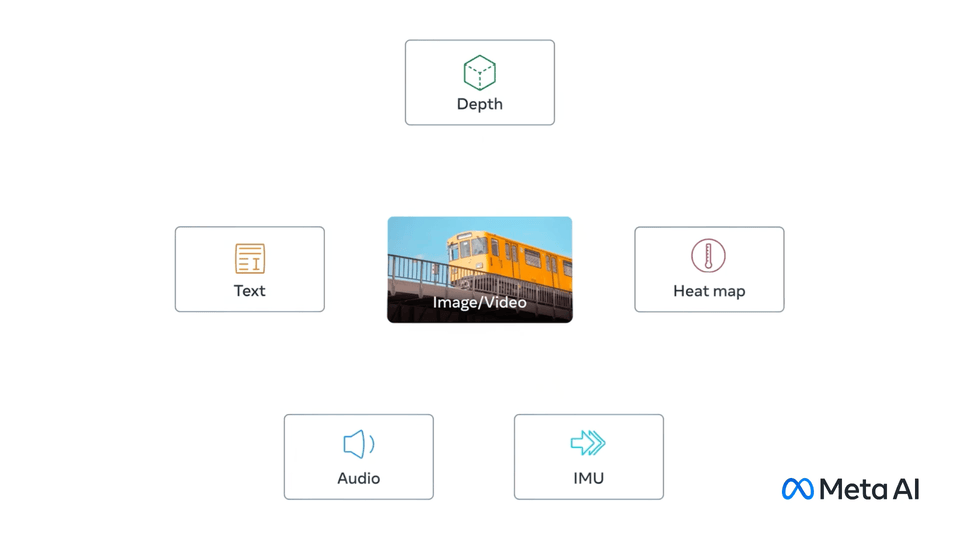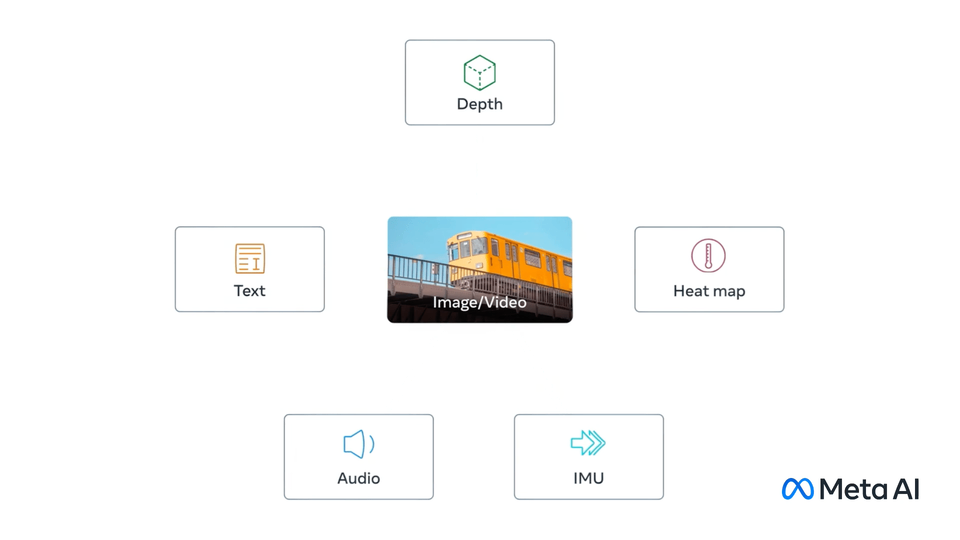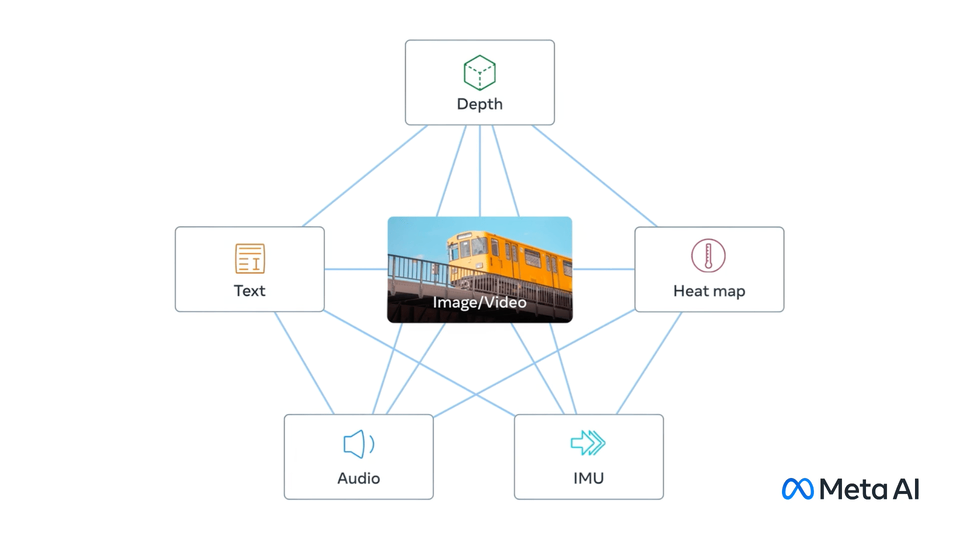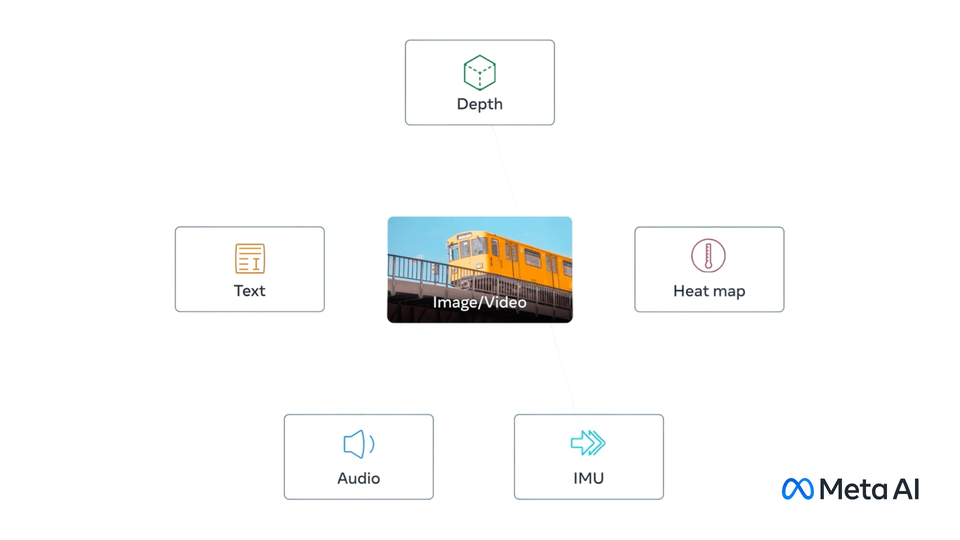
Unified Embedding Space: IMAGEBIND aligns six different data modalities into a single, shared space. This allows for innovative applications like cross-modal retrieval, where an audio clip could help find a related image, or even generating images from audio descriptions.
Emergent Zero-Shot Capabilities: By leveraging large-scale image-text data and naturally occurring paired data (like video-audio pairs), IMAGEBIND can perform zero-shot recognition tasks across different modalities without needing explicit training for each combination.
Coordinated Representation of Data: IMAGEBIND utilizes a coordinated representation of various data types, enabling seamless integration and interaction across modalities.
No Need for Complete Datasets: Unlike traditional models, IMAGEBIND doesn’t require datasets where all modalities co-occur. Instead, it leverages the binding property of images, aligning each modality’s embedding to image embeddings, which leads to emergent alignment across all modalities.
Leveraging Web-Scale Data: IMAGEBIND uses web-scale (image, text) paired data and combines it with naturally occurring paired data such as (video, audio), (image, depth), etc., to learn a single joint embedding space. This allows implicit alignment of text embeddings to other modalities like audio and depth.
Powerful Emergent Behavior: By aligning each modality's embedding to image embeddings, IMAGEBIND demonstrates powerful emergent zero-shot behavior, automatically associating pairs of modalities without needing specific training data for those pairs.

Ref : https://arxiv.org/pdf/2305.05665
Contrastive Learning:
Contrastive learning is a powerful technique that ImageBind uses to train its models. Here's how it works:
Pair Comparisons: The method involves comparing pairs of examples. Some pairs are related (positives) like an image and its description, while others are unrelated (negatives) like an image and a random, unassociated text. These comparisons can be made within the same type of data or across different types (modalities).
Unified Embedding Space: The goal is to create a shared space where related examples are close to each other, and unrelated examples are far apart. For example, ImageBind can align pairs such as (image, text), (audio, text), (image, depth), or (video, audio) by adjusting their embeddings to show these relationships.
Context-Specific Embeddings: While this approach works well for the specific pairs it trains on, the embeddings (representations) created for one type of pair might not work directly for different types of tasks because each pair type has its unique context and characteristics.
Zero-shot Image Classification in ImageBind:
Zero-shot image classification is a technique that allows models to classify images without having been directly trained on labeled image data. Here’s how it works and how ImageBind enhances it:
Text Prompts and CLIP: Following the method popularized by CLIP, this approach uses text prompts. It works within a shared (image, text) embedding space, where the model has been pre-trained with pairs of images and text descriptions. For classification, the model creates a list of text descriptions for the classes in a dataset. When a new image is presented, the model compares it to these text descriptions in the embedding space to find the closest match.
Expanding Capabilities with ImageBind: While traditional zero-shot classification relies on pre-training with image-text pairs, ImageBind extends this capability to other types of data. It enables zero-shot classification for modalities that do not have paired text data, such as audio or point-clouds. This means ImageBind can classify different types of data using the same zero-shot approach, making it more versatile and powerful.
Architectural Details:
IMAGEBIND employs a contrastive learning approach to align each modality’s embeddings with image embeddings. Here's a high-level overview of its architecture:
Image Encoder: Uses a Vision Transformer (ViT) to process images.
Other Modality Encoders: Includes encoders for text, audio, depth, thermal, and IMU data, each converting their respective inputs into embeddings.
Contrastive Learning: Utilizes a loss function that encourages embeddings from paired data (like an image and its audio) to be close in the shared space, while pushing unpaired data apart.
Alignment of different modalities is achieved by encoding each image Ii and its corresponding observation in the other modality Mi into normalized embeddings qi = f(Ii) and ki = g(Mi), where f and g are deep networks that learn to extract features from images and other modalities, respectively.
The training process uses an InfoNCE loss function, which compares how well these embeddings align with each other. This loss function penalizes the model when embeddings of related pairs (image and corresponding modality) are not similar enough, while ensuring they are distinct from unrelated pairs in the same mini-batch. The goal is to make the embeddings qi and ki closer in the joint embedding space, effectively aligning the image Ii with its paired modality Mi. This alignment helps to learn a unified representation that captures meaningful relationships between different types of data.
ImageBind aligns different modalities by training them together in pairs (I, M), where I is an image and M is another modality. This training not only aligns each modality with images but also causes an emergent alignment between pairs of modalities (M1, M2). Even though ImageBind is trained only with pairs like (I, M1) and (I, M2), it can effectively align M1 and M2 in the embedding space. This behaviour enables the model to perform tasks like zero-shot classification and cross-modal retrieval without needing direct training examples for those specific modalities (M1, M2).
Preprocessing in ImageBind:
ImageBind uses a sophisticated preprocessing approach to handle various types of data, ensuring they are effectively aligned and processed. Here’s a breakdown:
Vision Transformer (ViT) for Images and Videos: ImageBind employs a Vision Transformer (ViT) architecture to process visual data. For images, ViT divides the image into patches and processes them one by one. For videos, it adapts by extending its patch projection to manage frames from 2-second clips.
Audio as Spectrograms: Audio inputs are transformed into spectrograms, which are like images. Each 2-second audio clip is sampled at 16kHz and converted into 128 mel-spectrogram bins. This conversion treats audio as a 2D signal, using ViT with a patch size of 16 and a stride of 10 to process the spectrograms.
Thermal and Depth Images: These types of images are treated as single-channel images and encoded using ViT. Depth images are specifically converted into disparity maps to maintain scale invariance, following established methodologies.
Text Encoding: Inspired by CLIP, ImageBind uses a dedicated text encoder to process text data, ensuring it aligns well with other modalities.
Each type of data has its own encoder, which includes a specific linear projection head to create fixed-size embeddings. These embeddings are then normalized and optimized using the InfoNCE loss function, facilitating effective alignment and learning across different types of data within ImageBind.
Comparison to Prior Work:
Unlike methods like AudioCLIP and AVFIC that train with paired (audio, text) data, ImageBind achieves strong retrieval and classification results without direct training on audio-text pairs. Specifically, on benchmarks like Clotho for audio text retrieval, ImageBind outperforms AVFIC significantly, showcasing double the performance. It also competes favorably with AudioCLIP on audio classification tasks like ESC, despite AudioCLIP benefiting from supervised training using class names from AudioSet.
Additionally, ImageBind shows robust text-to-audio and text-to-video retrieval capabilities on MSR-VTT 1k-A, demonstrating its versatility in aligning modalities using images as a bridge, which enhances performance over traditional retrieval models like MIL-NCE.
In few-shot audio classification, ImageBind outperforms the AudioMAE model significantly across various settings, achieving approximately 40% higher accuracy in top-1 accuracy on ≤4-shot classification. It also matches or exceeds the performance of a supervised AudioMAE model on ≥1-shot classification tasks, showcasing its robustness in utilizing image alignment for audio tasks.
Similarly, in few-shot depth classification, ImageBind demonstrates superiority over the multimodal MultiMAE ViT-B/16 model across all evaluated settings.
ImageBind enables the composition of information across modalities, such as combining image and audio embeddings to retrieve images that reflect both concepts, like fruits on trees with birds chirping.
In ImageBind, the effectiveness of aligning modalities hinges significantly on the quality of image embeddings. Scaling the image encoder size while keeping other modality encoders fixed enhances the performance of emergent zero-shot classification for depth, audio, thermal, and IMU modalities within ImageBind. By increasing the capacity of the image encoder, ImageBind likely achieves better alignment between visual information and other modalities, thereby enhancing its ability to generalize and perform tasks across diverse data types without explicit paired training.
Experimentation and Results insights:
Pretrained CLIP Models: Using pretrained models like ViT-B, ViT-L, and ViT-H, it was found that stronger visual features, especially from ViT-H, significantly improved performance. For example, in depth and audio classification tasks, ViT-H improved accuracy by 7% and 4% compared to ViT-B.
Training Duration: Longer training periods enhanced zero-shot performance for both depth and audio across all datasets.
Image Augmentation: During training, paired images were augmented using basic techniques (cropping, color jitter) or stronger methods (RandAugment, RandErase). Stronger augmentation was beneficial for depth classification, especially with limited (image, depth) pairs from datasets like SUN RGB-D.
Audio Tasks: For audio tasks, using strong video augmentation made the task too challenging, leading to a 34% decrease in accuracy on the ESC dataset.
Encoder Size: Smaller encoders improved performance for depth tasks due to the limited size of the (image, depth) dataset. Conversely, larger encoders enhanced performance for audio tasks, particularly when paired with high-capacity image encoders.
Batch Size: The optimal batch size varied by modality. For image-depth tasks, smaller batch sizes were more effective due to the limited and less diverse dataset. In contrast, larger batch sizes worked better for audio-video alignment tasks, which had more positive and negative pairs.
Temperature in Contrastive Loss: The temperature parameter, a scaling factor in the contrastive loss function, was crucial. A fixed temperature generally produced better results for depth, audio, and IMU tasks. Higher temperatures worked best for training depth, thermal, and IMU encoders, while lower temperatures were optimal for audio tasks.
Generalization Across Modalities: The results show that ImageBind can generalize well across different types of data by using pre-trained encoders from OpenCLIP, such as ViT-H for images. For example, it adapts to grayscale depth rendering by representing depth information using grayscale values, demonstrating its versatility and robust preprocessing capabilities.
Applications and Future Directions
Multimodal Retrieval: Finding related content across different types of media, like matching a sound to a video or an image to a piece of text.
Audio-Based Detection: Enhancing object detection models to recognize objects based on sound inputs.
Generative Models: Using audio inputs to guide image generation in models like DALLE-2, expanding the creative possibilities for artists and designers.
Conclusion:
IMAGEBIND represents a significant leap forward in multimodal AI, demonstrating the power of unified embeddings to bridge the gap between different types of data. Its ability to learn from image-paired data and apply this knowledge across various modalities without explicit training sets a new standard for versatility and efficiency in AI models.
As AI continues to evolve, methods like IMAGEBIND will pave the way for more integrated and intuitive interactions between humans and machines, making technology more accessible and effective across numerous applications.
Want to explore more on multimodality, Check out our detailed blog on multimodal AI here!