
Introduction: Multimodality
Imagine a world where machines can see, hear, and even feel, just like humans. This concept, known as multimodality, refers to the ability to process and understand different types of sensory information simultaneously. For instance, when we walk on a beach, we perceive the sight of the ocean, the sound of waves, and the feeling of sand under our feet. These different types of information are called modalities. Multimodal learning, a field within artificial intelligence, focuses on creating models that can interpret and integrate these various modalities. This approach is particularly important for technologies like robots, which need to navigate and interact with the real world by making sense of diverse sensory inputs. By leveraging multiple modalities, we can develop a more comprehensive and accurate understanding of our surroundings, enhancing the capabilities of AI systems in numerous applications such as healthcare, retail, entertainment, autonomous vehicles. Geoffrey Hinton, a pioneer in deep learning, said: "Understanding intelligence is going to require a real understanding of the interactions between different sensory modalities."
Key Concepts in Multimodal Learning
Shared Representation
Creating a compact and unified understanding from different types of sensory data. For instance, recognizing the concept of "ocean" through the sight of a beach, the sound of waves, and the feeling of sand. It helps in building more accurate and robust models.
A major obstacle in learning a joint embedding is the absence of large quantities of multimodal data where all modalities are present together.
Efficiently estimating the latent variables from observed data, despite the intractability of exact computations.

Ref : https://arxiv.org/pdf/2207.02127
Cross-Modal Generation
The ability to translate information from one modality to another. For instance, Imagining the sound of waves and the feeling of sand when looking at a picture of a beach. It enables better interaction and understanding across different types of sensory data.
If we have a way of embedding all modalities into a shared representation and generating modalities from it, then we can achieve generation between arbitrary modalities.
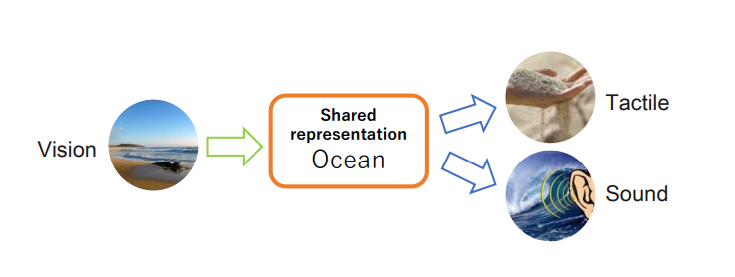
Ref: https://arxiv.org/pdf/2207.02127
Representation using Multimodal generative models
In learning a shared representation, different modalities are assumed to have complementarity for a given task, i.e., one modality contains information about a task that is unavailable in other modalities.
Researchers addressing multimodal data challenges, characterized by heterogeneous feature spaces and distributions among different modalities, have proposed generative model-based approaches. These approaches treat multimodal data as stochastically generated from a shared latent variable, facilitating the creation of a unified representation. This allows for inference of the latent variable across modalities, enabling cross-modal generation. Deep generative models, like variational autoencoders (VAEs), leverage deep neural networks to represent generative distributions and handle high-dimensional data effectively.
- X is the entire dataset, made up of many samples.
Each sample is denoted as X(i), which includes several modalities (like pictures, text, and sounds) represented as X(i)m.
The feature space Xm is the specific format or characteristics of one type of information.
We use data(X) to represent the actual, true distribution of the combined data from all these modalities.
Sometimes, we look at only a part of the information in a sample, which is denoted as X(i)k (a subset of the full sample X(i)).
Finally, we introduce a representation z(i) that captures the essence of all the different types of information in a sample. This is called the shared representation, and it helps to unify the different modalities into a single, meaningful format.
The shared representation must be easy to obtain even in the absence of some modalities and should generate new information. For example, we can take a picture and generate a corresponding piece of text or sound from it. By using the shared representation, we can convert or generate one type of information from another.
The model assumes that each type of data (modality) is conditionally independent given the latent variable z. This means that, once you know z, knowing one type of data doesn't give you any more information about another type.
The probability of the data and the latent variable together is given by:
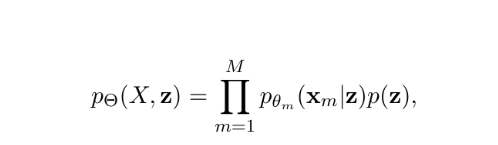
Here, X is the combined set of all modalities.
Xm is the data from the m-th modality.
pθm(xm∣z) is the probability of the m-th modality given the latent variable z.
p(z) is the probability of the latent variable itself.
Θ={θm} (m=1 to M) is the set of all parameters for the model.
Representation using Deep Neural Networks
Deep generative models use deep neural networks to represent complex probability distributions. Deep generative models can handle large and complex datasets directly because they use neural networks with multiple layers.
These models can be trained end-to-end, meaning the entire system is optimized together using backpropagation, which adjusts the model's parameters to minimize errors.
Examples of deep generative models include variational autoencoders (VAEs), which learn to encode and decode data to generate new samples; generative adversarial networks (GANs), where two networks compete to improve the generation quality; autoregressive models that predict data sequentially; and flow-based models that transform simpler distributions into more complex ones. These models are powerful tools for tasks like generating realistic images, text, or other types of data based on patterns learned from large datasets.
Variational AutoEncoders (VAEs)
Objective of VAEs: VAEs are models designed to learn useful representations of data, like images or text. They aim to capture the underlying structure or features that explain the data.
Key Components:
Encoder (qφ(z|x)): This part of the VAE learns to map input data (like images) to a distribution of latent variables (z). It is like a function that compresses the input data into a set of numbers (z) that represents its essential features.
Decoder (pθ(x|z)): The decoder reconstructs the original data from these latent variables (z). It's like a reverse process of the encoder, generating data similar to the input based on the latent variables.
Maximizing ELBO: Instead of directly maximizing the likelihood of the data, which is complex and often intractable, VAEs maximize the Evidence Lower Bound (ELBO) which is a lower bound approximation that consists of:
Reconstruction Loss: Measures how well the decoder reconstructs the input data from the latent variables. It checks how close the generated image is to the original.
Lrecon=Eqϕ(z∣xI)[logpθ(xI∣z)]+Eqϕ(z∣xT)[logpθ(xT∣z)]
Regularization Loss (Divergence): Controls how closely the distribution of latent variables (qφ(z|x)) matches a predefined standard distribution (typically a normal distribution). This helps in learning more structured and organized representations of the data.
LKL=DKL(qϕ(z∣xI)∥p(z))+DKL(qϕ(z∣xT)∥p(z))
Once a probability distribution is formed for a particular kind of modality, it can be used to represent that modality even when it is missing in a new record. The surrogate inference distribution associated with the available modality is used to estimate the latent variables. This estimation is based on the learned relationship between the modality and its corresponding latent space representation. For example, if an image modality is present but the text modality is missing, the model uses the learned qφ1(z|x1) to infer z, leveraging the characteristics encoded in the image.
When Z is missing, the model uses the learned conditional distribution P(Z∣X,Y) which can be expressed in terms of the latent variables as:
P(Z∣X,Y)=∫P(Z∣z)q(z∣X,Y)dz
Independence of Modalities: Each modality (e.g. images, text) has its own surrogate inference distribution (e.g. qφ1(z|x1) for images and qφ2(z|x2) for text). These distributions are learned independently during the training phase. This a key advantage of Variational Autoencoders (VAEs) compared to traditional autoencoders. VAEs are probabilistic models, meaning they can explicitly represent the uncertainty and variability in data.
While Generative Adversarial Networks (GANs) are powerful for generating diverse and realistic data, they struggle with handling different types of data distributions and dimensions simultaneously. Most GAN models are either conditional or unidirectional, meaning they can't easily handle diverse data types. Moreover, GANs often face challenges like mode collapse, where they generate limited varieties of outputs, especially in complex, multimodal datasets. As a result, VAEs have become more popular for multimodal data tasks, with GANs sometimes used alongside VAEs to enhance the quality of generated data or to manage distribution differences in VAEs' learning processes.
Co-ordinated v/s Joint Representation:
In coordinated models, each modality is processed independently, and their outputs are combined later. This approach is simpler but may not capture complex interactions between modalities effectively. In contrast, joint models integrate different modalities from the beginning, allowing for more nuanced understanding and representation of multimodal data. They are typically more complex to train but can yield better performance in tasks where modalities influence each other significantly. Below figure depicts graphical models of two categories of multimodal deep generative models. In this figure, the number of modalities is assumed to be two. The grey circles represent the observed variables and the white ones represent the latent variables. The black arrows represent the generating process of random variables, while the dotted ones represent the inference distributions. Furthermore, the orange two-way arrow indicates that the two latent variables are in the same space.
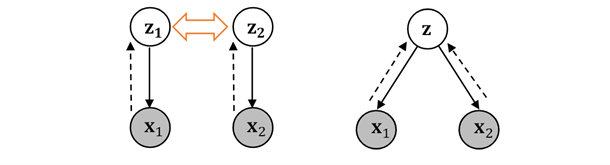
Left: the coordinated model; Right: the joint model.
Ref: https://arxiv.org/pdf/2207.02127
Co-ordinated Representation:
The coordinated model aims to align the distributions of latent variables (z) learned from different modalities (like images and symbols) so they are similar or interchangeable. This means making sure that the representations extracted from different types of data are compatible and can be used together effectively.
During training, the coordinated model simultaneously optimizes reconstruction and regularization loss alongside the ELBO for each modality x1, x2,…., xn. The goal is to find latent variable distributions (qφ1(z1|x1), qφ2(z2|x2)) that are both similar across modalities and effective for reconstructing each modality's data.
Joint Representation:
The goal of joint models is to create a shared representation space (latent space) that integrates information from multiple modalities (like images and text) into a single coherent framework. This shared space allows the model to understand relationships and dependencies between different types of data.
Loss Function: LVAE(X)=Eqϕ(z∣X)[log pθ(X∣z)]-KL[qϕ(z∣X)p(z)]
Eqϕ(z∣X)[log pθ(X∣z)] maximizes the likelihood of generating all modalities X from the latent variable z, and KL[qϕ(z∣X)p(z)] measures how different the inferred distribution qΦ(z∣X) is from a prior distribution p(z).
Modality-Specific Latent Variables: We must ensure that model can learn distinct representations for each modality while also capturing shared information. This is achieved by introducing modality-specific latent variables and optimizing them alongside the joint inference. It acts as a common representation space where information common to all modalities can be encoded and shared, facilitating cross-modal interactions and joint inference.
Each modality Xi has a specific latent variable zi and shares a common latent variable zs.
Encoders qϕi(zi∣Xi) and qϕs(zs∣X1,X2,,XM) learn the latent variables.
Decoders pθi(Xi∣zi,zs) reconstruct each modality using both latent variables.
The objective function maximizes the ELBO for each modality and this shared representation, ensuring the model captures both distinct and shared information.
Weakly-supervised learning
Weakly-supervised learning addresses scenarios where not all combinations of modalities are present in the training data. The goal of weakly-supervised learning is to train the joint VAE model even when some modalities are absent. This is done by adapting the training process to work with subsets of modalities that are present in the data.
One approach involves sub-sampling during training. This means that instead of requiring all modalities for every data point, the model can be trained using only a subset of modalities that are available in each training example.
Another method focuses on learning the relationships between different modalities. The model learns to maximize the joint likelihood of the available modalities while minimizing the likelihood of negative samples (modalities that are not present). For example, if a dataset includes images and corresponding text descriptions, the joint likelihood would capture how likely it is to see a specific image-text pair together in the dataset. On the contrary, in a dataset containing images and text, a negative sample could be an image paired with a randomly chosen text description that does not correspond to that image.
Representing Modalities:
Early fusion (Feature Level Fusion):
It involves combining feature representations from different modalities at an early stage, typically before any significant processing or analysis occurs. This means that raw or processed features from each modality are concatenated or combined into a single representation which is then fed into the learning model.
Advantages:
The model can potentially capture complex interactions and correlations between modalities more effectively.
It can be straightforward to implement and computationally efficient, especially when dealing with simple feature representations.
Works well when all modalities have dense and informative feature representations.
Disadvantages:
Combining features directly can lead to a high-dimensional feature space, which might require more computational resources and could lead to overfitting.
Performance heavily relies on the quality and relevance of the features extracted from each modality.
Late fusion (Decision Level Fusion):
It involves processing each modality independently through separate models, generating individual decisions or predictions, and then combining these decisions at a later stage, often through voting or averaging.
Advantages:
Allows each modality to be processed using specialized models, which can optimize performance based on specific characteristics of each modality.
Can handle missing modalities or incomplete data more gracefully, as each modality's model operates independently.
Disadvantages:
May not fully capture complex interactions between modalities.
Separate models might redundantly learn similar aspects of data, leading to increased computational cost and complexity.
Hybrid fusion (Combining Early and Late Fusion):
It combines aspects of both early and late fusion techniques. This approach aims to leverage the strengths of each method to achieve better overall performance in multimodal learning tasks.
Advantages:
Allows for more sophisticated modelling by combining early integration of feature-level interactions with late-stage integration of decision-level outputs.
Can handle diverse data types and varying degrees of modality availability more effectively.
Disadvantages:
Hybrid fusion methods can be more complex to implement and optimize compared to early or late fusion alone.
May require additional computational resources compared to simpler fusion methods.
Other Fusion Techniques:
Weighted Fusion: Assigning different weights to modalities based on their relevance or importance.
Hierarchical Fusion: Incorporating multiple levels of fusion (e.g., both early and late) to capture hierarchical relationships among modalities.
State-of-Art-Technologies in Multimodality Models:
CLIP (Contrastive Language-Image Pre-training):
Developed by OpenAI, CLIP learns joint representations of images and text using a contrastive learning framework. It can associate images with their corresponding textual descriptions without requiring explicit image labels during training.
DALL-E:
Also from OpenAI, DALL-E generates images from textual descriptions using a variant of the GPT architecture. It demonstrates the ability to create novel visual content based on textual prompts.
GPT-4 (Generative Pre-trained Transformer 4):
The successor to GPT-3, GPT-4 is anticipated to incorporate advancements in multimodal capabilities, potentially integrating text with other modalities like images and audio for more comprehensive understanding and generation tasks.
CLIP-4:
An extension of CLIP, CLIP-4 is expected to enhance multimodal capabilities further, improving the model's ability to understand and generate content based on both textual and visual inputs.
Gemini:
Developed by Google Research, Gemini is a multimodal AI model that integrates advanced language understanding with capabilities to interpret and generate responses based on both text and images.
ImageBind (Meta AI)
It excels in accurately delineating objects within images, crucial for applications like medical imaging and autonomous driving. It leverages advanced convolutional neural networks (CNNs) and segmentation techniques to achieve state-of-the-art results, making it ideal for tasks requiring precise object localization and extraction from images. The most important feature of ImageBind is that it can work on 6 different modalities together.
Conclusion:
In a nutshell, multimodality represents a significant leap forward in the field of artificial intelligence, allowing machines to perceive and interpret the world through multiple sensory inputs just as humans do. By integrating data from various modalities, such as vision, sound, and touch, we can build more robust and versatile AI systems. These advancements have far-reaching implications across numerous industries, from healthcare and retail to entertainment and autonomous vehicles. As research and technology continue to evolve, the potential for multimodal learning to enhance our interaction with AI grows exponentially. Embracing this multidisciplinary approach will undoubtedly lead to smarter, more intuitive, and more effective solutions, transforming the way we live and work. The journey of multimodality is just beginning, and its future holds exciting possibilities for both technological innovation and real-world applications.