
Contents
In the expanding world of Artificial Intelligence (AI), the ability to efficiently manage and process massive and complex datasets is critical. As AI applications evolve, ranging from image analysis to voice recognition and recommendation systems, the data they work with becomes increasingly sophisticated. This complexity has led to the rise of vector databases. Unlike traditional databases built to store simple, scalar information, vector databases are specifically architectured to manage multi-dimensional data, commonly referred to as vectors. These vectors can be visualized as entities defined by both direction and magnitude within a multi-dimensional space. With AI and machine learning continuing to shape the digital landscape, vector databases have become vital for the storage, retrieval, and analysis of high-dimensional information.
As an instance, imagine asking a chatbot a question and it instantly fetches exactly what you need, not by keyword matching, but by understanding the meaning behind your words. Or think about an app that finds visually similar images from a billion-picture database within seconds. These experiences are powered by an often-overlooked concept: vector databases.
In the era of AI and large language models (LLMs), unstructured data like text, images, and audio has exploded. Traditional relational databases aren’t built to handle these complex, high dimensional representations. That’s where vector databases step in. There are various vector databases available in the market, few of them are shown in below figure.
In this article, we’ll explore what vector databases are, why they are critical for modern AI, and compare three of the top options in the market today which are: Pinecone, FAISS, and Chroma.
What is a Vector Database?
At a basic level, a vector database stores vectors; numeric representations of data. Instead of rows and columns of text or numbers, it stores high-dimensional points. Unstructured data, things like text, images, or audio etc. doesn’t fit into standard database tables because it lacks a fixed format. To make such data usable for AI and machine learning models, it’s transformed into structured, numeric representations called embeddings.
Embeddings work by encoding complex data into a compact, meaningful format. Whether it's a sentence, a photo, or a piece of sound, embeddings capture the essence of the information in numerical form, allowing machines to process and compare them efficiently. Think of it like condensing a long novel into a meaningful summary without losing the key ideas. This conversion is typically powered by specialized neural networks (techniques like Word2Vec, BERT, CLIP, or sentence transformers) trained for the embedding task. For instance, word embeddings map similar words close to each other in vector space, making relationships easier for algorithms to detect.
In essence, embeddings act as translators; turning messy, unstructured content into organized numeric patterns that machine learning models can easily interpret, recognize patterns from, and make intelligent decisions based on. The real magic happens with similarity search. When you query a vector database, it doesn't look for exact matches; instead it looks for the closest vectors using distance metrics like cosine similarity or Euclidean distance. Below diagram depicts how vector database plays crucial role in semantic search operation.
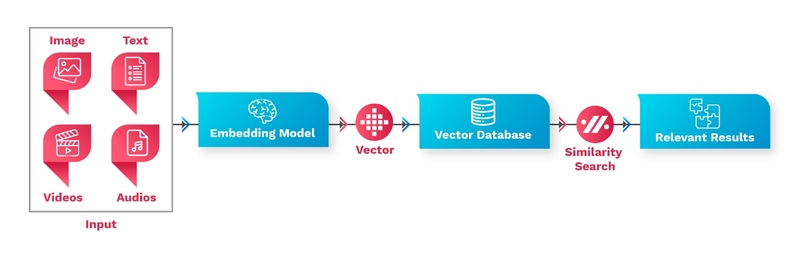
Figure: Semantic Search using Vector database
Example: If you search for “healthy recipes” a vector database would find content that's semantically similar; like “nutritious meals”, even if the exact phrase isn't present. In short: Vector databases turn “search by keywords” into “search by meaning”.
Traditional Database vs. Vector Database
The table below contrasts traditional databases with vector databases, highlighting the shift from exact, structured data retrieval to semantic, high-dimensional similarity search using unstructured embeddings.

Why Vector Databases Matter for AI Applications
Today’s AI isn’t just about processing structured data; it’s about understanding human context across billions of unstructured files. Here’s why vector databases are essential:
Semantic Search: Powering AI-driven search engines that think beyond exact words.
Recommendation Systems: Suggesting similar products, songs, or content.
RAG Systems (Retrieval-Augmented Generation): Helping LLMs like GPT-4 access external knowledge sources in real-time.
Image and Audio Retrieval: Matching not just identical, but similar mages, voices, or sounds.
Without efficient storage and retrieval of high-dimensional vectors, these advanced AI features would be painfully slow or downright impossible at scale.
Key Features of a Good Vector Database
When evaluating a vector database for AI applications, one should look for various key features shown in below figure:
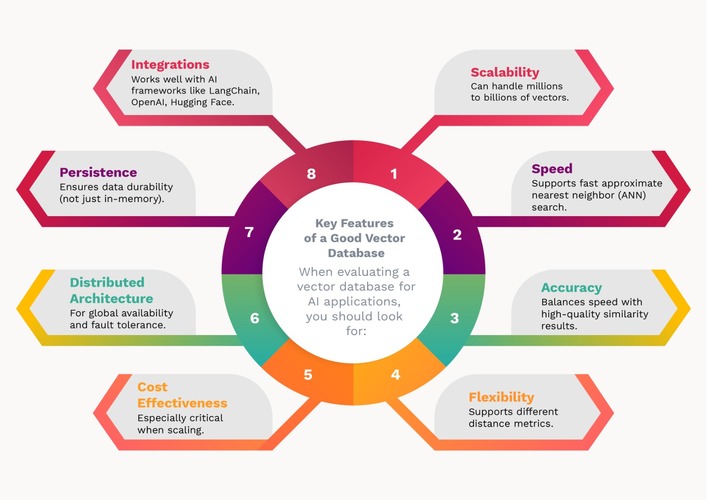
Figure: Key features of good vector database
Deep Dive: Pinecone vs FAISS vs Chroma
Let’s now look at the leading players in the vector database space.
Pinecone:
Pinecone is a fully-managed, vector database-as-a-service, designed specifically for production AI applications. It is the most suitable choice for Startups and enterprises needing production-ready semantic search, chatbots, or recommender systems, without worrying about infrastructure. Below are the strengths and weaknesses of Pinecone.
Strengths:
Fully cloud-managed, no servers to set up.
Hybrid search: metadata vector search together.
Integrations with OpenAI, LangChain, Cohere, and more.
Handles billions of vectors with low-latency retrieval.
Weaknesses:
Higher cost, especially as usage scales.
Less customizable for developers who want deep tuning.
FAISS:
FAISS (Facebook AI Similarity Search) is a highly-optimized, open-source library developed by Meta. It enables efficient vector search and clustering, especially at massive scale. It is the most suitable choice for Tech teams that want maximum control and performance for high-throughput AI systems, at the cost of operational complexity. Below are the strengths and weaknesses of FAISS.
Strengths:
Blazing fast performance on CPU or GPU.
Extremely customizable: one can choose the index type, quantization, sharding strategies.
Free and open source, perfect for budget-sensitive projects.
Weaknesses:
One must manage hosting, scaling, persistence on their own.
No built-in multi-tenancy or management dashboard.
Chroma:
Chroma is an open-source vector database optimized for AI-native workflows. It focuses on simplicity, ease of integration, and developer experience. It is best for Researchers, and early-stage startups building MVPs, internal tools, or research prototypes. Below are the strengths and weaknesses of Chroma.
Strengths:
Super easy to install and run locally or on small servers.
Tight integration with LangChain and emerging AI stacks.
Excellent for quick prototyping and research projects.
Weaknesses:
Not yet battle-tested for ultra-massive production loads.
Some features (like distributed clustering) are still maturing.
Applications of Vector Databases
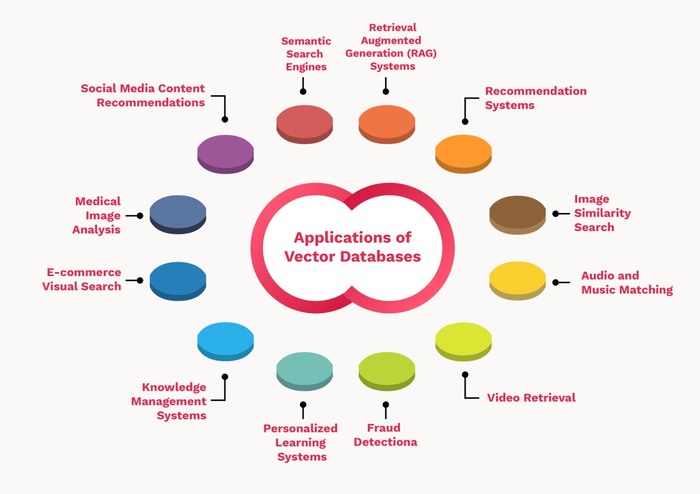
Figure: Applications of Vector Databases
Conclusion
Vector databases are quietly becoming the foundation of AI innovation, just like relational databases once powered the web era. From improving chatbot accuracy to enabling next-generation search and discovery systems, they’re unlocking what’s possible when AI meets scale. Whether you pick Pinecone, FAISS, or Chroma, the key is understanding your own needs first because the best database is always the one that matches your goals, not just the biggest name. As AI applications continue to grow in complexity and ambition, choosing the right vector database might just be the most important infrastructure decision you’ll make.