Contents
In today’s digital world, a vast amount of critical information is still locked away in physical documents, scanned PDFs, and images. Optical Character Recognition (OCR) has emerged as a powerful technology that bridges this gap enabling machines to read text from images and convert it into structured, searchable, and editable data. Whether you're extracting data from invoices, digitizing books, or automating document processing workflows, OCR plays a vital role across industries. Now let's conduct a comprehensive, end-to-end exploration of Optical Character Recognition from foundational concepts to advanced techniques.
Introduction: What, Why, How of OCR
What is OCR?
OCR is a technology that enables machines to recognize and extract text from non-digital formats such as scanned documents, images, handwritten notes, or printed books. At its core, OCR transforms visual data into machine-encoded text, enabling search, indexing, analysis, or downstream automation.
Why is OCR Important?
The world is filled with unstructured or semi-structured documents. From printed invoices and handwritten prescriptions to historical manuscripts and ID cards, extracting usable information from these sources is essential for digital transformation. OCR allows organizations to:
Automate manual data entry and reduce errors
Improve accessibility for visually impaired users
Enable document searchability and archival
Integrate paper-based workflows with digital systems
How Does OCR Work?
OCR may seem like magic, but it’s actually a multi-stage process that combines image processing, computer vision, and increasingly, deep learning. The system first enhances the image, identifies regions containing text, then recognizes characters or words, and finally performs post-processing to improve accuracy.
Modern OCR solutions leverage deep learning models such as CNNs, RNNs, and Transformers to handle complex layouts, multiple languages, low-resolution scans, and even handwritten text. OCR can be rule-based (e.g., template matching), or AI-driven, and it may run offline (on-device) or online (via cloud APIs).
OCR Pipeline
1. Image Acquisition
Input formats: scanned documents, PDFs, images from camera
Formats supported: JPEG, PNG, TIFF, PDF, etc.
Challenges: glare, blur, shadows, resolution
2. Image Pre-processing
Goal: Enhance image quality for better recognition
Grayscale conversion
Binarization (thresholding)
Noise removal (blurring, morphological operations)
Deskewing (correcting image tilt)
Resizing / Normalization
Contrast enhancement
3. Text Detection (Layout Analysis)
Goal: Identify areas in the image that contain text
Segmentation: separating text from non-text regions
Line/Word/Character detection
Bounding box generation for each detected region
Algorithms:
Traditional: Connected Component Analysis (CCA), MSER
Deep Learning: CRAFT, EAST, YOLO-based detectors
4. Text Recognition
Goal: Convert detected text regions into characters or words
Character segmentation (if needed)
Sequence recognition using:
Traditional: Template matching, heuristics
ML-based: CNN + RNN + CTC loss pipelines
Transformer-based: TrOCR, Donut (OCR without bounding boxes)
5. Post-processing
Goal: Improve text accuracy and structure
Spell check / dictionary matching
Named Entity Recognition (NER)
Correction using context models
Format restoration (paragraphs, tables, forms)
6. Structured Output Generation
Goal: Convert raw text into useful formats
Output formats: JSON, CSV, XML, or searchable PDFs
Field/key-value pair extraction (e.g., "Invoice Number", "Date")
Table reconstruction (row-column structure)
7. Integration & Usage
Goal: Feed OCR data into downstream systems
RPA tools, data lakes, document management systems
Search engines (indexing OCR data)
Analytics pipelines
Auto-tagging, classification, compliance
Types of OCR Techniques: Traditional to Advanced
OCR systems have evolved from simple pixel-based methods to complex deep learning pipelines. Based on the sophistication of technology, we can broadly divide OCR techniques into traditional rule-based methods and modern machine learning-based engines.
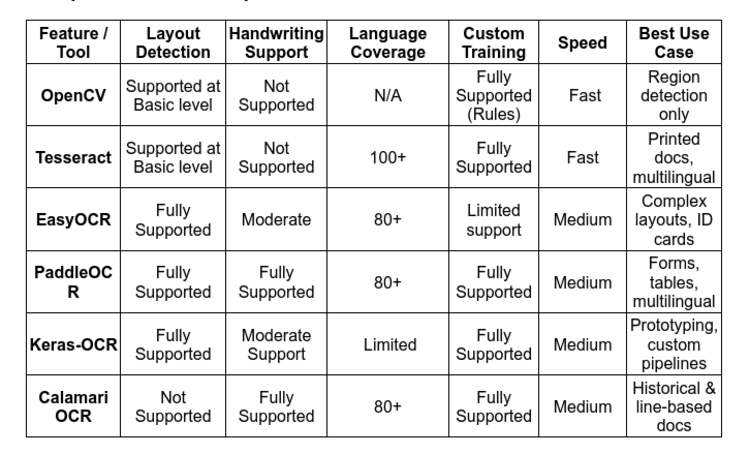
3.1 Traditional Approach: OpenCV (Pre-OCR Text Detection)
OpenCV is not an OCR engine itself, but it's widely used in the preprocessing or text detection stage. It helps locate potential text regions in images using classical image processing techniques like:
Thresholding / Binarization
Contour detection
Edge detection (Canny)
Morphological transformations
Connected Component Analysis (CCA)
These methods work well for clean, high-contrast documents with simple layouts but fail when documents are noisy, distorted, or have handwriting.
Strengths: Fast, lightweight, interpretable
Weaknesses: Not robust to variation, can't recognize text, only detects regions
3.2 Modern Open-Source OCR Engines
Let’s explore the most widely used open-source OCR libraries, each leveraging deep learning to improve recognition accuracy.
Tesseract OCR
Developed by HP; now maintained by Google.
Uses LSTM-based recognition in v4+.
Supports over 100 languages.
Can be trained on custom fonts or languages.
Pros: Mature, language-rich, supports PDF output
Cons: Struggles with complex layouts and handwriting; layout detection is basic
EasyOCR
Built on PyTorch with deep learning.
Supports 80+ languages.
No need for bounding boxes; detects + recognizes end-to-end.
Good for complex and noisy layouts.
Pros: High accuracy, easy to use, supports mixed scripts
Cons: Slightly slower, not great for very large documents
PaddleOCR
Developed by Baidu; based on PaddlePaddle framework.
Offers full pipeline: detection, recognition, table extraction.
Supports multilingual OCR, layout analysis, key-value pair extraction.
Active development and model hub.
Pros: Modular, accurate, great for forms and tables
Cons: Heavier, dependency on PaddlePaddle (less common than PyTorch/TensorFlow)
Keras-OCR
Built on Keras/TensorFlow.
Includes CRNN + CTC-based recognizer.
Easy to customize and extend.
Good as a learning or prototyping tool.
Pros: Customizable, simple architecture
Cons: Not production-ready out of the box, fewer features than others
Calamari OCR
Focused on line-based recognition, built for historical documents.
Uses ensemble of neural networks.
Works well with Fraktur, cursive, and degraded prints.
Pros: Great for historical, non-Latin scripts
Cons: Line-level input required, not suitable for layout-heavy modern docs
Comparative Table of Open-Source OCR Tools