
Contents
Understanding CLIP Embedding and Architecture
CLIP (Contrastive Language–Image Pretraining) is a model developed by OpenAI that learns to connect images and text through a contrastive learning approach. The goal of CLIP is to enable zero-shot image recognition and facilitate tasks like image-text similarity and text-driven image generation.
What Are CLIP Embeddings?
CLIP embeddings are vector representations of text and images that capture their semantic meanings. The embeddings are created in such a way that semantically similar text and images are mapped close to each other in a shared vector space. This property makes it possible to perform tasks like matching captions to images or retrieving relevant images based on textual descriptions.
Key Properties of CLIP Embeddings:
Unified Space: Both images and text are encoded into a shared embedding space, allowing cross-modal tasks.
Semantic Alignment: Similar concepts, whether visual or textual, have similar embeddings.
Zero-Shot Generalization: Since CLIP is trained on a wide variety of image-text pairs, it generalizes well to tasks without requiring task-specific training.
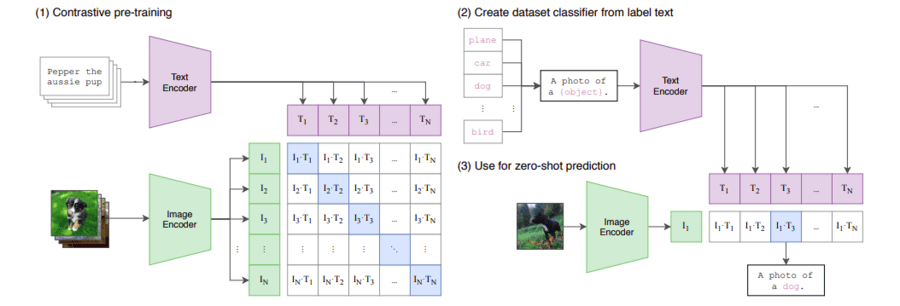
CLIP Architecture
CLIP consists of two main components as shown in the below Image:
Image Encoder
Text Encoder
Both components are trained simultaneously using a contrastive learning objective.
1. Image Encoder
The image encoder processes images to produce vector embeddings. It can use architectures like:
Vision Transformer (ViT): Processes the image as a sequence of patches and learns representations using self-attention mechanisms.
ResNet: A convolutional neural network (CNN) that extracts features from images.
The output is a fixed-size vector representing the image in the shared embedding space.
2. Text Encoder
The text encoder converts textual inputs into embeddings. It is typically based on a transformer architecture, like the ones used in large language models. The text is tokenized, and the embeddings are derived from the processed tokens.
Shared Embedding Space
Both the image and text encoders project their respective inputs into a shared latent space. This alignment enables cross-modal retrieval tasks.
Training Objective
CLIP uses a contrastive learning objective:
A batch contains NN image-text pairs.
For each pair, the model tries to:
Maximize the similarity between the embeddings of the paired image and text.
Minimize the similarity between non-matching image-text pairs.
The similarity is measured using the cosine similarity.
The loss function used is a symmetric InfoNCE (Information Noise-Contrastive Estimation) loss, which is applied across both modalities.
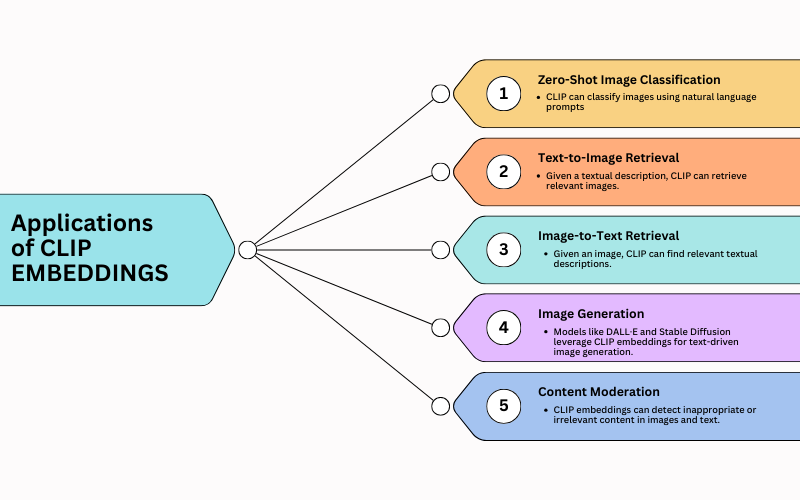
Applications of CLIP
Zero-Shot Image Classification: CLIP can classify images using natural language prompts (e.g., "a photo of a cat").
Text-to-Image Retrieval: Given a textual description, CLIP can retrieve relevant images.
Image-to-Text Retrieval: Given an image, CLIP can find relevant textual descriptions.
Image Generation: Models like DALL·E and Stable Diffusion leverage CLIP embeddings for text-driven image generation.
Content Moderation: CLIP embeddings can detect inappropriate or irrelevant content in images and text.
Advantages of CLIP
Robustness: Performs well on datasets it has never seen during training.
Versatility: Can handle a wide range of downstream tasks without task-specific fine-tuning.
Efficiency: Enables efficient cross-modal retrieval.
Challenges and Limitations
Bias in Training Data: Since CLIP is trained on large, uncurated datasets, it can inherit biases present in the data.
Dependence on Training Quality: The quality of image-text alignment in the training data heavily affects CLIP's performance.
High Computational Cost: Training CLIP requires significant computational resources.
Conclusion
CLIP embeddings and architecture revolutionize the way we think about connecting images and text. By training a shared embedding space for both modalities, CLIP enables a wide range of innovative applications. Despite its challenges, CLIP's potential for generalization and versatility has made it a cornerstone for many modern AI applications.