
Introduction
Artificial intelligence (AI) has transformed the way we interact with technology, enabling systems to process and understand various forms of data. Within this domain, a significant distinction exists between unimodal and multimodal models. Both fall under the AI-ML umbrella, yet they operate differently in terms of representation, capabilities, and applications. In this blog, we'll explore these differences, highlight the advantages of multimodal models, and delve into real-world use cases and applications.
What are Unimodal and Multimodal Models?
Unimodal models are designed to process data from a single modality. For instance, a text classification model focuses solely on textual data, while an image recognition model works exclusively with visual data. These models are effective for tasks that require analysis of one type of input but are inherently limited in their ability to integrate and reason across diverse data types.
Multimodal models, on the other hand, process and combine information from multiple modalities—such as text, images, audio, and video—to generate a unified understanding. A great example is Google's multimodal model, Gemini, which can analyze a photo of a plate of cookies and generate a written recipe as a response, or vice versa. This ability to integrate diverse data types boosts AI's comprehension and enables it to excel in more complex tasks.
Why Multimodal Models needed?
Multimodal models are an evolution of generative AI, which traditionally created new content like text, images, or videos from single-type prompts. By leveraging multiple data types simultaneously, these models enable:
Enhanced Understanding: Multimodal systems excel in interpreting complex situations by integrating diverse inputs. For example, combining textual descriptions with visual imagery leads to better context comprehension.
Improved Performance: Integrating data from various modalities often results in more accurate predictions and robust outcomes compared to unimodal models.
- Flexibility and Modularity: Multimodal models are inherently adaptable, capable of handling various tasks and inputs without requiring extensive retraining for each type of data.
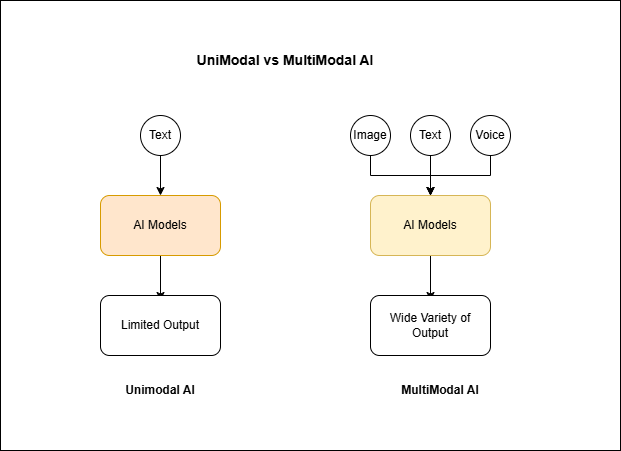
Representation Differences: Unimodal vs. Multimodal
Data Handling:
Unimodal: Processes data from a single source, such as only text or only images.
Multimodal: Integrates and learns from multiple data sources simultaneously.
Learning:
Unimodal: Focused feature extraction within one domain.
Multimodal: Cross-modal learning, where the model identifies patterns and correlations across different modalities.
Output:
Unimodal: Task-specific outputs, like a label for an image or sentiment score for a text.
Multimodal: Contextual and versatile outputs, like generating text descriptions for an image or creating audio from textual prompts.
Functioning of Multimodals
Multimodal AI models combine data from various sources like text, video, and audio. They train individual neural networks on specific data types. For example, using recurrent neural networks for text and convolutional neural networks for images.
After being processed by unimodal encoders, the data is combined in the fusion network. This network merges features from different data types into a single representation using techniques like attention mechanisms, concatenation, and cross-modal interactions.
The classifier makes accurate predictions or categorizes fused representations into specific output categories, serving as the final component of the model's architecture.
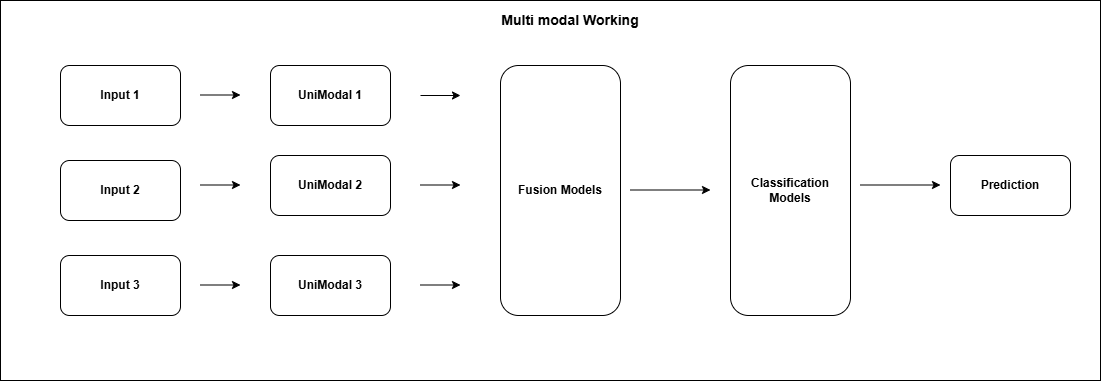
Key Components Driving Multimodal Models
Visual Information Processing:
Leveraging state-of-the-art computer vision techniques to analyze and extract meaningful insights from visual content.
Advanced architectures like Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) excel in tasks like detecting objects, interpreting scenes, or analyzing video feeds.
Linguistic Understanding Modules:
Employing sophisticated natural language processing (NLP) tools to interpret and generate human-like text.
Transformers, such as GPT and BERT, process textual data for tasks ranging from translation to sentiment analysis. Newer architectures like T5 are used for cross-modal text generation.
Data Integration Techniques:
Combining multimodal information through efficient fusion strategies to create a unified representation.
Strategies like joint embeddings, cross-modal transformers, and attention mechanisms prioritize and align crucial features across data types.
Audio Signal Analysis:
Audio components play a key role in applications involving speech recognition, sentiment analysis, and sound-based diagnostics.
Models like Wav2Vec analyze audio inputs, complementing text and image data for tasks such as transcription or video analytics.
Context-Aware Interaction Layers:
Contextual layers help models understand temporal and spatial relationships between inputs, such as aligning spoken instructions with visual actions.
Graph neural networks (GNNs) and temporal attention layers enable dynamic reasoning by correlating events over time.
Applications of Multimodal Model
Audio-Visual Speech Recognition (AVSR)
Audio-Visual Speech Recognition (AVSR) uses both what we hear and what we see to better understand speech, especially when it's hard to hear clearly, like in noisy places. This approach combines lip movements we see with the sounds we hear to make speech recognition more accurate. It helps by picking up extra details that make understanding speech easier, like how our brain combines sight and sound.
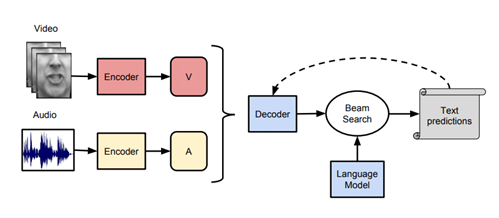
Image Source : Link
Multimedia Content Indexing and Retrieval
Multimedia Content Indexing and Retrieval is about organizing and finding videos and other media online. Multimodal models help by looking at both visual and other types of information together. They can automatically find where scenes change in videos (shot-boundary detection) and create summaries of videos. This makes it easier to search and manage large collections of multimedia files, like videos and images, on the internet.
Multimodal Interaction and Affective Computing
Multimodal Interaction and Affective Computing use models to understand how people behave and feel in social situations. This field also looks at affective computing, which uses data from different sources (like voice and facial expressions) to automatically assess mental health conditions.
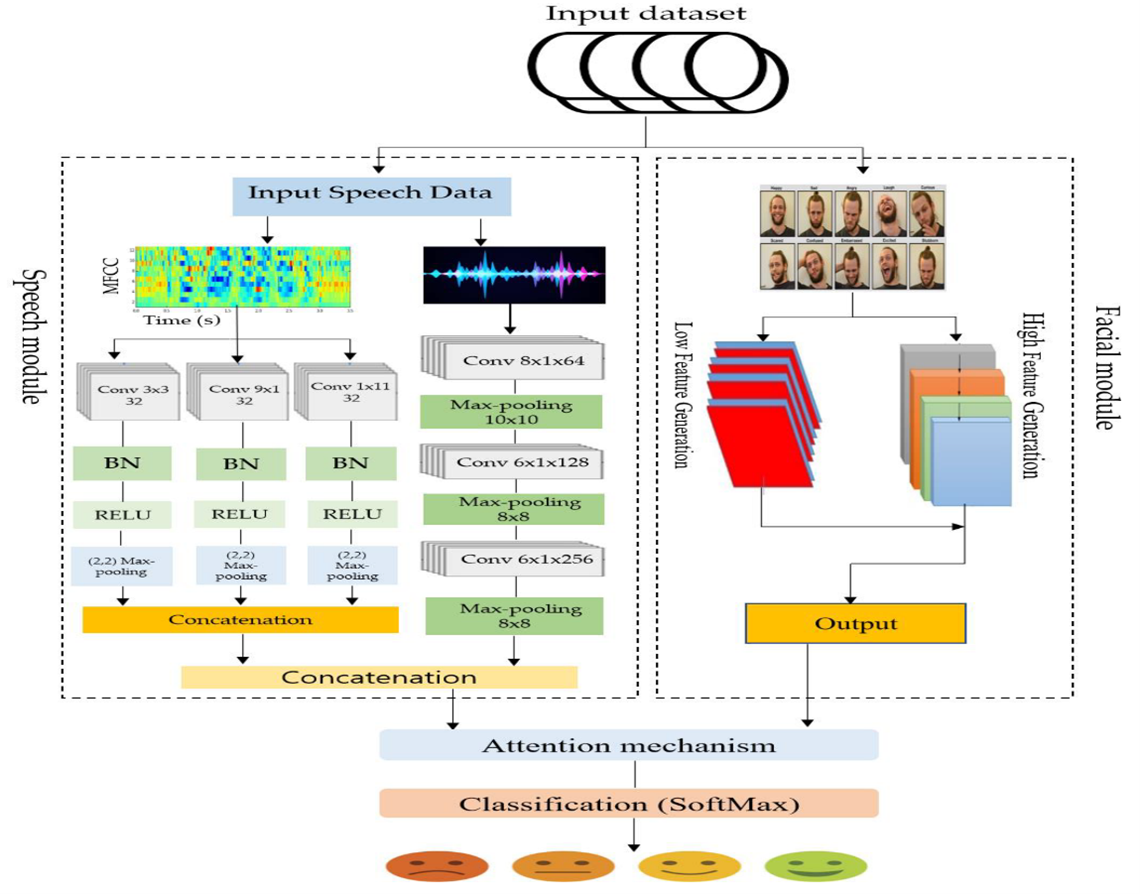
Ref: https://www.mdpi.com/1424-8220/23/12/5475
Language and Vision: Media Description
This helps create captions for images and answer questions about what's within the pictures (Visual Question-Answering). These models generate written descriptions of what's happening in visuals, which is useful for helping people who are visually impaired in their daily tasks. However, there are still challenges in making sure these descriptions are accurate and useful in everyday situations.
Autonomous Driving and Robotics:
In autonomous driving and robotics, multimodal models integrate data from sensors (like cameras and lidar for vision) and other inputs (like GPS and radar). This enables vehicles and robots to perceive their environment accurately and make informed decisions in real-time.

Image Source : Link
Virtual Assistants and Human-Computer Interaction:
Virtual assistants like Siri, Alexa, and Google Assistant use multimodal models to understand and respond to user queries using both voice and text inputs. These models integrate speech recognition, natural language processing, and visual data to provide more intuitive and context-aware interactions.
Conclusion:
Unimodal models are precise and effective for specific tasks but lack the contextual richness offered by multimodal systems. Multimodal AI represents the future, bridging the gap between different data types to create seamless, intelligent, and adaptive solutions. The ability to understand and process diverse inputs makes multimodal models more human-like in their reasoning and decision-making capabilities. "The beauty of AI lies in its ability to mimic the interconnectedness of human perception, and multimodal models are a step closer to achieving that." As industries continue to evolve, the potential of multimodal AI will unlock new horizons, paving the way for more integrated and efficient technologies. Whether it's enhancing creativity, solving complex problems, or improving accessibility, multimodal models stand at the forefront of the AI revolution.