
Quantization has gained significant traction in the field of large language models (LLMs) due to its ability to drastically reduce model size and resource requirements, making it possible to deploy and run these complex models on smaller GPUs or edge devices. We will be exploring what's the fundamental behind them and what we achieve by using them.
a. Why Quantization Is Famous in the LLM Domain
1. Efficiency and Accessibility:
- Large language models (LLMs) like GPT or PaLM require substantial computational resources for both training and inference. Quantization reduces the memory footprint and computational demand, enabling even resource-constrained environments to run these models.
2. Cost Reduction:
- Smaller models mean lower hardware requirements and energy consumption, translating to cost savings for businesses and researchers deploying these models at scale.
3. Compatibility with Existing Models:
- Post-training quantization allows existing pre-trained models to be adapted without requiring a complete retraining cycle, making it an attractive option for rapid optimization.
b. How Quantization Enables Big Models to Run on Small GPUs

1. Compression of Weights and Activations:
- Quantization reduces the number of bits required to represent model weights and activations. For instance, converting 32-bit floating-point weights to 8-bit integers results in a 4x reduction in memory usage.
2. Bit-Width Reduction:
- By using fewer bits (e.g., 8-bit, 4-bit) to represent data, quantized models maintain most of their representational power while using significantly less storage and compute.
3. Efficient Hardware Utilization:
- GPUs and specialized accelerators, like TPUs, are often optimized for low-bit arithmetic operations, enabling faster inference when running quantized models.
4. Tradeoff Between Compression and Accuracy:
- Quantization is designed to balance the reduction in model size with minimal degradation in accuracy. Techniques like mixed precision or quantization-aware training (QAT) can be used to fine-tune this balance.
c. Need for Quantization :
Quantization is essential for reducing hardware requirements during model inference, enabling large language models (LLMs) to run on consumer-grade hardware.
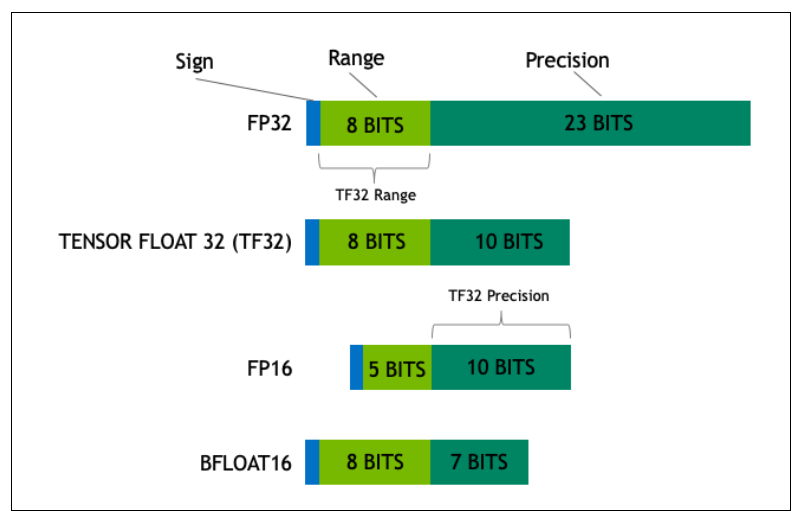
The size of a machine learning model is determined by its number of parameters and the precision used to represent them. Precision is typically in formats like float32 (FP32), float16 (FP16), or bfloat16 (BF16). For instance:
- FP32 (32-bit floating-point):
- 1 bit for the sign, 8 bits for the exponent, and 23 bits for the mantissa (fraction).
- Commonly referred to as "full precision" and requires 4 bytes per parameter.
- BF16 (16-bit brain floating-point):
- 1 bit for the sign, 8 bits for the exponent (same as FP32), and 7 bits for the mantissa.
- Along with FP16, it is classified as "half precision," requiring only 2 bytes per parameter.
Research has shown that reducing precision from 4 bytes (FP32) to 2 bytes (FP16/BF16) results in minimal information loss. Therefore, quantization is a preferred technique to compress model size while maintaining accuracy, making LLMs more efficient and accessible for deployment.
So if we have to check the model size then we can multiply floating precision with the number of parameters as shown below.

d. Key Measure: Bits-Per-Element vs. Model Complexity
Quantization is evaluated based on the bits-per-element metric, which directly impacts the tradeoff:
- Lower bits-per-element: Higher compression but potential accuracy loss.
- Higher bits-per-element: Retains accuracy better but requires more resources.
In summary, quantization's ability to strike an optimal balance between performance, accuracy, and resource efficiency makes it an essential technique for scaling down large models to smaller hardware without significant compromises.
e. Sample Quantization :8-Bit Quantization
Beyond the 2-byte precision formats (FP16 and BF16), models can be further compressed using **8-bit quantization**, which represents parameters using only 1 byte (8 bits). This approach significantly reduces memory usage while retaining enough information for effective inference.
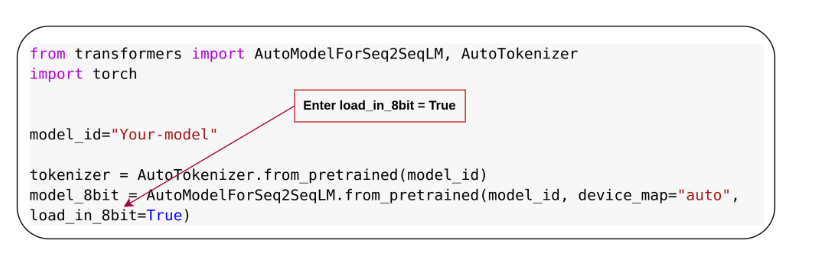
f. Loading Models in 8-Bit Precision
When using the Hugging Face library, loading a model in 8-bit precision is straightforward. Simply set the parameter `load_in_8bit=True` during model initialization. Ensure that the required libraries, bitsandbytes and accelerate, are installed on your system to enable this functionality.
This further reduction in precision allows large models to run efficiently on consumer-grade hardware without compromising much on performance.
That’s all for this blog, we will be discussing further how the performance changes with adoption of this technique in our further blogs.