
The Voice Revolution: Applications, Challenges, and Future of Automatic Speech Recognition
Introduction
In the ever-evolving landscape of technology, one area that has shown significant promise and growth is Automatic Speech Recognition (ASR). ASR enables humans to interact with computer systems using their voice, converting spoken language into text in real time. It is a key component of many modern applications, offering a seamless interface between humans and machines. While ASR is not yet at the point of achieving fully autonomous, human-like communication, it has made remarkable progress, enabling a wide range of practical applications.
ASR refers to the capability of a system to process and transcribe human speech into written text. Unlike voice recognition—which focuses on identifying the speaker—ASR emphasizes understanding and transcribing spoken language accurately. Modern ASR systems often incorporate Natural Language Processing (NLP), allowing them to interpret and respond to user commands in a conversational manner.
For example:
When you ask Siri for the weather forecast, ASR transcribes your speech and NLP interprets the intent behind your words.
Similarly, Google Assistant uses ASR to understand your spoken queries and provide relevant responses.

Importance of ASR in Today’s World
The importance of ASR technology cannot be overstated in the digital age, where efficiency and convenience are paramount. It enables hands-free control of devices, making technology more accessible to users with disabilities or those in environments where typing is impractical. ASR has found applications across various domains:
Smart Assistants: Siri, Alexa, and Google Assistant use ASR to provide instant answers, reminders, and smart home control.
Customer Service: Automated phone systems can transcribe and interpret user requests, enabling quick and efficient support.
Healthcare: Doctors use ASR systems for clinical note-taking, saving time and reducing administrative burden.
Live Captioning: ASR is critical for creating subtitles during live broadcasts and improving accessibility for hearing-impaired individuals.
Examples of Popular ASR Systems
ASR has become an integral part of many popular consumer and business platforms:
Siri: Apple’s smart assistant, capable of understanding and executing a wide variety of voice commands.
Google Assistant: Known for its robust ASR capabilities and integration with Google’s ecosystem.
Amazon Alexa: Widely used for smart home automation and voice-based shopping.
Microsoft Cortana: Aimed at productivity and workplace integration.
Zoom’s Live Transcription: Helps users by providing real-time captions during meetings.
The advancements in ASR technology are not just about convenience but also about transforming the way humans interact with machines. By bridging the gap between spoken language and machine understanding, ASR is paving the way for more natural, intuitive, and inclusive communication in our increasingly digital world.
Key Components of ASR
The architecture of the ASR can be understood as below with Feature Extraction and the decoding process as shown in below image.
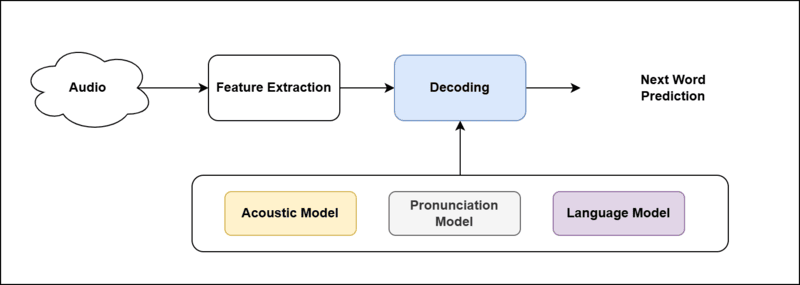
The feature extractor transforms the raw audio waveform into a compact, informative representation that captures the essential characteristics of speech while discarding irrelevant details, such as noise. This representation is used as input to the acoustic model.
The effectiveness of ASR systems hinges on three key components of the decoding process:
Acoustic Model
The acoustic model translates audio signals into phonetic representations by analyzing patterns in speech.
Role of Spectrograms and MFCCs: Spectrograms visualize the frequency content of audio signals over time, while MFCCs capture essential features for distinguishing phonemes. These representations are fed into the acoustic model for processing.
Language Model
The language model predicts the most likely sequence of words, ensuring the transcription is coherent and contextually accurate.
Training on Large Corpora: The performance of the language model heavily depends on training with large and diverse datasets, which helps the system learn grammatical structures, idiomatic expressions, and domain-specific vocabulary.
Pronunciation Model
The pronunciation model maps written words to their corresponding phonetic representations, bridging the gap between text and speech.
Importance: Accurate pronunciation models are essential for recognizing words with multiple pronunciations or those from different languages and dialects.
ASR Pipeline
Automatic Speech Recognition (ASR) is a sophisticated technology that converts spoken language into written text. This process involves multiple intricate steps and relies on cutting-edge technologies to ensure accuracy and reliability. Below, we break down how ASR works and the key technologies behind it. The ASR process can be divided into several stages, each playing a crucial role in transforming raw audio into meaningful text.
Speech Input (Audio Capture)
Audio signals are captured using a microphone or recording device. This stage involves converting vibrations of sound waves into an electrical signal, which is then digitized for processing.
Challenges: Background noise, variations in speech accents, and recording quality can affect the accuracy of the audio capture.
Acoustic Signal Processing
The captured audio is preprocessed to remove noise and improve clarity. Techniques such as noise reduction and normalization are applied to ensure the audio signal is clean and consistent.
Feature Extraction
Key features of the audio signal are extracted to represent speech in a form that the system can analyze. Commonly used techniques include spectrograms and Mel-frequency cepstral coefficients (MFCCs), which break down the audio signal into its fundamental components.
Importance: This step reduces the complexity of the data while retaining the essential elements needed for accurate speech recognition.
Acoustic Model:
The acoustic model takes the extracted features as input.It maps these features to probabilities over phonemes, subword units, or other linguistic representations.
This mapping bridges the gap between the audio signal and the linguistic representation of speech.
Language Modeling
A language model predicts the most likely sequence of words based on the extracted features. This step ensures that the system can account for grammar, syntax, and contextual relevance.
Decoding and Transcription
The final step involves decoding the processed audio into text. Using algorithms, the system matches patterns from the acoustic and language models to generate the most accurate transcription.
Technologies Behind ASR
ASR systems rely on a combination of traditional and modern machine learning techniques:
Deep Learning
Modern ASR systems leverage deep learning models to improve accuracy and adaptability. These models can handle large datasets and learn complex patterns, making them ideal for speech recognition.
Neural Networks
Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTMs): These models are designed to process sequential data, making them suitable for handling speech, which unfolds over time.
Transformer Models: The latest advancements in ASR often utilize transformers, which excel at parallel processing and handling long-term dependencies in data.
Traditional Approaches
Hidden Markov Models (HMMs): Widely used in earlier ASR systems to model the temporal structure of speech.
Gaussian Mixture Models (GMMs): Used in combination with HMMs to represent the probability distribution of speech features.
Though less common in modern systems, HMMs and GMMs laid the foundation for contemporary ASR technologies.
Applications of ASR
Automatic Speech Recognition (ASR) has revolutionized how humans interact with technology, offering diverse applications that improve convenience, accessibility, and efficiency. Below are some of its prominent use cases:
Personal Assistants and Smart Devices
ASR powers virtual assistants like Siri, Alexa, and Google Assistant, enabling hands-free control over devices and services. It allows users to perform tasks like setting reminders, controlling smart home devices, or checking the weather using voice commands.
Customer Service (IVR Systems)
Interactive Voice Response (IVR) systems use ASR to guide customers through automated menus, reducing the need for human agents and improving efficiency. These systems can handle inquiries, route calls, and provide solutions based on voice inputs.
Accessibility for People with Disabilities
ASR enhances accessibility by enabling voice-driven interfaces for individuals with mobility or vision impairments. It also assists in converting spoken language to text for individuals who are deaf or hard of hearing.
Real-Time Transcription for Meetings
ASR tools like Zoom and Otter.ai provide live transcription of meetings and conferences, improving inclusivity and enabling participants to focus on discussions without worrying about taking detailed notes.
Voice Search and Commands
ASR is integral to voice search, helping users quickly find information online. It also facilitates hands-free operation of devices, such as searching for content on streaming platforms or navigating through apps.
Language Learning and Education Tools
Educational applications leverage ASR to help users practice pronunciation, improve language skills, and engage in interactive learning experiences. These tools provide immediate feedback, making language learning more effective and personalized.
Challenges in ASR
Despite its advancements, ASR faces several challenges that affect its performance and adoption discussed as under:
Variability in Accents, Dialects, and Pronunciation
ASR systems often struggle with understanding diverse accents, regional dialects, and unique pronunciations, leading to lower accuracy in global applications.
Background Noise and Poor Audio Quality
Noisy environments and low-quality audio recordings can hinder the ability of ASR systems to accurately transcribe speech, especially in real-time applications.
Ambiguity in Language
Homophones (e.g., "read" and "reed") and context-dependent words create challenges for ASR systems, which may generate incorrect transcriptions without sufficient contextual understanding.
Resource-Intensive Model Training
Training ASR systems requires large datasets and significant computational resources, which can be prohibitive for smaller organizations or low-resource languages.
Ethical Concerns
Data Privacy and Security: Collecting and storing voice data raises concerns about user privacy and the potential misuse of sensitive information.
Bias in Training Data: ASR systems may exhibit biases due to underrepresentation of certain languages, accents, or demographics in training datasets, leading to unequal performance.
Popular ASR Frameworks and Tools
Various frameworks and tools are available to implement ASR systems, catering to both open-source enthusiasts and enterprises:
Open-Source Tools
Kaldi: A highly flexible toolkit widely used in research and industry for building ASR models.
CMU Sphinx: An early open-source ASR system, ideal for basic applications and academic purposes.
Mozilla DeepSpeech: A deep learning-based ASR engine inspired by Baidu’s Deep Speech architecture.
Cloud-Based Solutions
Google Cloud Speech-to-Text: Offers features like speaker diarization, profanity filtering, and support for multiple languages.
Amazon Transcribe: Designed for scalable applications, with customization options for medical or legal use cases.
Microsoft Azure Speech Service: Provides real-time and batch transcription capabilities with customizable language models.
Emerging Tools and APIs
Innovative platforms like OpenAI Whisper and Deepgram focus on improving ASR accuracy, multilingual support, and advanced features like sentiment analysis.
Future of ASR
The future of ASR holds exciting possibilities:
Integration with Conversational AI and Chatbots
ASR will increasingly integrate with conversational AI systems to provide seamless, natural interactions in customer support, virtual assistants, and more.
Improvements in Multilingual Support
Future ASR systems will better handle code-switching and offer robust support for diverse languages and dialects, enabling more inclusive applications.
Advances in Zero-Shot and Few-Shot Learning
These techniques will allow ASR systems to adapt to new languages and domains with minimal data, making them more versatile.
ASR in Augmented and Virtual Reality
ASR will enhance AR/VR experiences by enabling natural voice interactions in immersive environments, revolutionizing gaming, education, and remote work.
Ethical and Inclusive Innovations
The focus will shift toward creating unbiased, privacy-preserving ASR systems that cater to a broader audience while addressing ethical concerns.
Conclusion
ASR technology has transformed communication and interaction across industries. From personal assistants to accessibility tools, its applications continue to grow. While challenges like data bias and resource constraints persist, advancements in deep learning, multilingual support, and ethical AI promise a bright future. We encourage readers to explore ASR tools, contribute to ongoing research, and share their experiences to foster innovation and inclusivity in this exciting field.