
Automatic Speech Recognition (ASR) has evolved significantly with advancements in deep learning. Traditional methods, such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs), have gradually been replaced by state-of-the-art techniques, including Transformer-based models, Deep Transfer Learning, Federated Learning, and Deep Reinforcement Learning. These methodologies have drastically improved ASR's accuracy, efficiency, and adaptability to real-world applications.
Recent progress in deep learning has made automatic speech recognition (ASR) more challenging. ASR needs a lot of training data, including sensitive information, and requires powerful computers and plenty of storage. Making ASR systems more adaptable helps them perform better in changing environments. However, DL methods usually assume that the training and testing data come from the same type of source, which isn’t always true. To tackle this, advanced DL techniques like deep transfer learning, federated learning, and deep reinforcement learning are used. DTL helps create high-quality models using small but related datasets. FL allows training on private data without actually collecting it. DRL helps systems make better decisions in real-time while keeping computing costs low.
This blog explores these methodologies and their impact on ASR's acoustic and language models while addressing open issues and key challenges. Additionally, we will cover the latest advancements, comparisons, and practical applications of ASR systems, along with possible future directions.
Evolution of ASR Systems
ASR systems have evolved through several stages:
Rule-Based Systems: Early speech recognition systems relied on hand-crafted phonetic rules.
Statistical Approaches: Hidden Markov Models paired with Gaussian Mixture Models led to improved recognition accuracy.
Deep Learning Era: The introduction of Deep Neural Networks outperformed HMM-GMM approaches by capturing intricate speech patterns.
End-to-End ASR: Sequence-to-sequence architectures, such as Connectionist Temporal Classification and Transformers, enabled ASR models to be trained without explicit phoneme modeling.
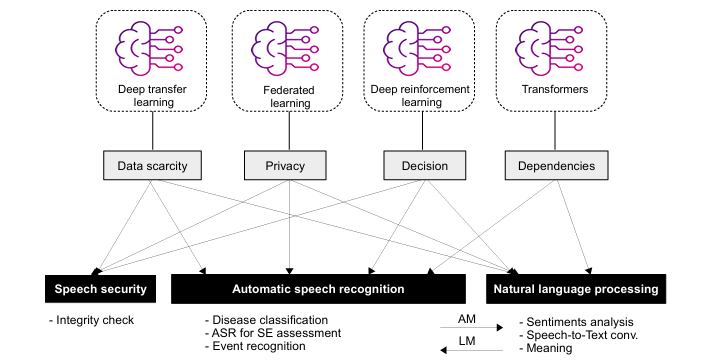
Figure: Summary of critical areas in speech processing where DTL, DRL, FL, and Transformers can be applied
Ref:(https://arxiv.org/pdf/2403.01255)
Background: Acoustic and Language Models
Acoustic Model
The Acoustic Model (AM) is responsible for capturing the sound characteristics of different phonetic units in speech. It transforms raw audio waveforms into statistical representations that enable speech recognition. Various feature extraction techniques, including Linear Predictive Coding (LPC), Cepstral Analysis, Filter-Bank Analysis, Mel-Frequency Cepstral Coefficients (MFCCs), and Wavelet Analysis, are used to generate characteristic vector sequences from speech signals.
Once the features are extracted, the decoding process begins, where a search algorithm (decoder) matches the acoustic signals with predefined phonetic units stored in an acoustic lexicon. This step is essential in constructing the hypothesized words or phonemes that form the basis of speech-to-text conversion. Improvements in AM, such as hybrid DNN-HMM models and end-to-end architectures like Transformers and Conformers, have significantly enhanced ASR accuracy. However, challenges such as background noise, speaker variability, and acoustic mismatches continue to affect model robustness.
Language Model
The Language Model (LM) plays a critical role in ASR by providing linguistic context to interpret speech correctly. It predicts the probability of word sequences, ensuring that recognized words form coherent and grammatically correct sentences. LMs are typically trained on extensive text datasets to capture vocabulary, syntax, and semantics.
Domain-specific LMs are trained to adapt to specialized terminologies, such as medical or legal language, making ASR more effective in targeted applications. The backoff n-gram model, neural network-based LMs, and Transformer-based architectures like BERT and GPT have significantly advanced ASR capabilities. However, challenges such as limited training data for low-resource languages, handling code-switching, and domain adaptation remain key areas of research.
Advancements in ASR Technologies
ASR systems often face performance degradation in certain situations due to the "one-model-fits-all" approach. Additionally, the lack of diverse and sufficient training data affects AM performance. To overcome these constraints and improve the resilience and flexibility of ASR systems, advanced DL methodologies such as DTL and its sub-field domain adaptation (DA), DRL, and FL have surfaced. These innovative methodologies collectively address issues concerning knowledge transfer, model generalization, and training effectiveness, offering remedies that expand upon the capabilities of traditional DL models within the ASR sphere. Thus, many research studies have focused on enhancing existing ASR systems by applying the aforementioned algorithms. Below Figure provides an overview of the current SOTA advanced DL-based ASR and its most useful related schemes in both AM and LM.

Figure: Overview of advanced DL-driven ASR algorithms and their commonly utilized models.
Ref:(https://arxiv.org/pdf/2403.01255)
Transformer-Based ASR
Enhancing Speech Recognition with Transformers
Transformers have emerged as the leading architecture in ASR due to their ability to process long-range dependencies efficiently. Unlike RNNs and CNNs, transformers utilize self-attention mechanisms, enabling them to capture complex acoustic and linguistic features effectively.
Figure: An example of CNN-based Transformer for automated audio captioning
Ref: https://arxiv.org/pdf/2403.01255)
Acoustic Modeling
Acoustic models form the foundation of ASR systems by transforming raw audio into phonetic representations. Transformers such as Conformer and Transformer-Transducer have introduced hybrid approaches, combining convolutional modules with self-attention mechanisms to enhance feature extraction. These methods significantly improve ASR performance in noisy environments and diverse acoustic conditions.
Transformers have significantly influenced acoustic modeling in ASR, but they also present unique challenges. One key issue is their susceptibility to input sparsity, meaning they struggle with incomplete or missing data compared to CNNs. To address this, researchers have introduced regularization techniques that adjust attention weights without requiring additional computation or module training, improving Transformer stability.
Another limitation of Transformer-based ASR models is that they often lack feature diversity when processing multiple input streams. A proposed solution is multi-level acoustic feature extraction, which combines both shallow and deep streams to capture traditional classification features along with speaker-invariant characteristics. Additionally, a feature correlation-based fusion (FCF) strategy helps merge these features effectively across frequency and time domains before passing them into the Transformer model.
Language Modeling
Language models predict word sequences and provide contextual understanding to ASR systems. Transformer-based models such as BERT and GPT have revolutionized ASR by improving sentence structure comprehension and reducing word error rates (WER). However, these models struggle with adapting to unseen dialects and domain-specific vocabulary, necessitating continual adaptation strategies.
A key finding is that upper self-attention layers can be replaced with feed-forward layers without a loss in performance. This insight, tested on datasets like Wall Street Journal (WSJ) and Switchboard (SWBD), suggests that lower self-attention layers capture enough contextual information, making a global view less necessary in upper layers.
A Transformer-based encoder-decoder model has also been developed to refine ASR output. This model, initialized with pre-trained BERT weights, improves transcription accuracy through data augmentation and weight initialization techniques. On the LibriSpeech benchmark, it significantly reduces WER, especially in noisy environments, and nearly matches the performance of Transformer-XL language model re-scoring with a 6-gram model.
One of the widely used techniques in ASR is Connectionist Temporal Classification (CTC). CTC enables alignment-free training, meaning it does not require predefined word boundaries. Instead, it learns to map speech to text sequences efficiently by using a blank symbol to handle variable-length alignments. A hybrid CTC-attention model combines the strengths of CTC with Transformers, maximizing the potential of both acoustic models and language models. In one approach, the wav2vec2.0 model was used for speech feature extraction, while a DistilGPT2 decoder helped improve contextual understanding.
Deep Transfer Learning (DTL) in ASR
Leveraging Transfer Learning for ASR Performance
Deep Transfer Learning enables ASR models to leverage knowledge from pre-trained models and adapt to new tasks with minimal labeled data. This is particularly useful for ASR applications in underrepresented languages and noisy environments.

Figure: Deep transfer learning principle.
Ref:(https://arxiv.org/pdf/2403.01255)
Acoustic Domain Adaptation
DTL enhances ASR's ability to generalize across different acoustic conditions by fine-tuning pre-trained models on domain-specific datasets. Techniques such as feature-space adaptation and online DTL improve robustness, but domain shifts and class imbalance remain challenges.
Researchers have explored using unsupervised pre-training for ASR to improve acoustic model (AM) performance. One study used the wav2vec model to process large amounts of unlabeled audio, boosting CNN-based speech recognition. Another study introduced a data augmentation strategy to improve ASR for children’s speech, using XLS-R wav2vec 2.0, a self-supervised, multilingual model trained on adult speech.
A multi-dialect acoustic model was developed using soft-parameter-sharing and multi-task learning. This method integrates dialect recognition with ASR by sharing parameters across tasks and balancing training with adaptive cross-entropy loss. As a result, error rates were significantly reduced, making ASR models more effective in recognizing different dialects.
Language Model Adaptation
DTL is also used to enhance language models (LMs) for ASR, often referred to as LM adaptation. These methods bridge the gap between different linguistic distributions, allowing ASR systems to better understand diverse speech patterns and languages.
One study introduced L2RS (Language-to-Rescoring Strategy), which utilizes Pre-trained NLP models like BERT to extract diverse textual features and Automatic weighting techniques to rescore ASR predictions, improving accuracy.
Recent advances in Sequence-to-Sequence (S2S) models have shown great potential for training monolingual ASR systems. A hybrid CTC-attention model combines CTC (Connectionist Temporal Classification) for alignment-free training and An encoder-decoder model that refines language predictions using past information.
Incorporating DTL in language models allows for improved text prediction and reduced error rates in specialized domains such as healthcare and legal transcription. However, transferring linguistic features between diverse languages and adapting cross-domain semantics are complex hurdles to overcome.
Federated Learning (FL) for ASR
Collaborative Learning for Privacy-Preserving ASR
Federated Learning (FL) is transforming ASR by enabling collaborative model training without sharing sensitive user data. Unlike traditional centralized training, where all data is collected in one location, FL allows machine learning (ML) models to be trained locally on multiple edge devices (e.g., mobile phones, laptops, private servers). These local models share only model updates (not raw data), ensuring privacy and security.
FL works by minimizing a global loss function across multiple clients (devices). Each client trains a local model on its own data and then shares only the necessary updates with a central server. The server aggregates these updates to improve the global ASR model. This iterative process is commonly managed using federated averaging (FedAvg), where local model updates are averaged to refine the central model.

Figure: Federated learning principle: (a) Horizontal FL, (b)Vertical FL.
Ref:(https://arxiv.org/pdf/2403.01255)
Types of Federated Learning in ASR
Horizontal Federated Learning (HFL):
Clients train a shared global model on datasets with the same feature space but different users (e.g., multiple hospitals training on patient speech data). The process includes initialization, local training, encryption, secure aggregation, and model updates.
Vertical Federated Learning (VFL):
Models are trained on datasets with the same users but different features (e.g., banks and e-commerce platforms collaborating without sharing raw data). Secure computation techniques like entity data alignment (EDA) and encrypted model training (EMT) ensure privacy.
Applications and Advancements in FL-Based ASR
FL-based ASR models have been developed with various enhancements to address real-world challenges. One of the major issues is the non-identically distributed (non-IID) nature of user data, where different speakers, environments, and accents create significant variations in training data. To address this, techniques such as random client data sampling, personalized model layers, and computational load redistribution have been introduced.
4. Deep Reinforcement Learning (DRL) for ASR
Optimizing ASR Systems with DRL
Deep Reinforcement Learning (DRL) introduces adaptive learning mechanisms that enable ASR models to optimize performance dynamically. By treating ASR as a sequential decision-making process, DRL techniques such as policy gradients and self-critical sequence training (SCST) improve recognition accuracy.
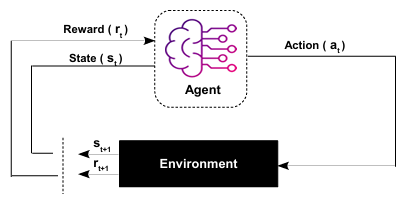
Figure: DRL principle
Ref:(https://arxiv.org/pdf/2403.01255)
In ASR, DRL is employed to bridge the gap between training and testing phases, which often leads to performance drops. The main issues addressed by DRL include:
Mismatch in Training and Evaluation Metrics: Traditional ASR training maximizes log-likelihood, whereas performance is measured using WER.
Teacher Forcing Dependency: During training, models rely on ground truth labels, but at test time, they must predict words based on previous outputs, leading to potential inconsistencies.
To resolve these discrepancies, Self-Critical Sequence Training (SCST) was developed. SCST treats the encoder-decoder ASR model as an agent, where each prediction step considers acoustic features and previous outputs. The reward function is based on WER improvements, ensuring the model optimizes toward better speech recognition accuracy.
Another DRL approach applies policy gradient methods to integrate user feedback into ASR, allowing models to learn from real-world corrections. Researchers have also explored AutoML-driven ASR optimization, where DRL automates compression techniques for large ASR models, such as low-rank matrix factorization (SVD). This method achieves over 5× model compression without degrading WER, improving efficiency in real-world applications.
Additionally, DRL has been used for speech enhancement models, optimizing noise reduction based on ASR performance. By leveraging low-rank factorization techniques, ASR systems achieve 3.7× speed improvements while maintaining recognition accuracy.

Figure: Example of sequential decision model of DRL-based ASR
Ref: (https://arxiv.org/pdf/2403.01255)
Open Issues and Key Challenges
Data Scarcity: ASR performance heavily depends on large datasets, which are scarce for many languages and dialects.
Computational Cost: Advanced models require high computational resources, limiting their deployment on edge devices.
Real-Time Processing: Current models struggle with achieving low-latency processing while maintaining high accuracy.
Privacy Concerns: Federated and decentralized ASR training pose challenges in secure aggregation and model updates.
Domain Adaptation: Ensuring ASR models generalize well across multiple domains remains a challenge.
Future Directions
To address these challenges, future ASR research should focus on:
Multimodal ASR: Integrating visual cues and contextual information to enhance speech recognition.
Self-Supervised Learning: Reducing dependency on labeled datasets through unsupervised and semi-supervised learning.
Edge Computing for ASR: Optimizing lightweight ASR models for real-time speech recognition on mobile devices.
Adaptive ASR Models: Developing models capable of continuous learning and domain adaptation.
Improved Privacy Mechanisms: Enhancing FL-based ASR with robust security protocols to protect user data.
To The Horizon
The integration of advanced deep learning techniques has revolutionized ASR systems, enabling enhanced accuracy, privacy preservation, and real-time speech processing. However, significant challenges remain in computational efficiency, data privacy, and model adaptation. Continued research and innovation will drive the development of more efficient, scalable, and intelligent ASR solutions in the future. Our team at FuturewebAI is providing AI Solutions boosting businesses. Connect with us to schedule a meeting.