Contents
In today’s AI-driven era, data is no longer limited to text. Businesses, researchers, and enterprises deal with a diverse range of information text documents, images, tables, videos, audio, and structured databases. Traditional Retrieval-Augmented Generation (RAG) systems have transformed how AI handles knowledge retrieval and contextual answer generation by combining the strengths of retrieval systems and large language models (LLMs). However, traditional RAG is primarily text-centric and fails when dealing with multimodal content such as scanned documents, images, tables, or videos. This limitation has created a strong need for Multimodal RAG systems, which extend the traditional RAG pipeline to handle multiple data modalities seamlessly, enabling richer, context-aware, and accurate responses.
RAG: Fundamental Understanding
Traditional Retrieval-Augmented Generation systems are designed to enhance the capabilities of large language models by combining retrieval-based search with generative AI. A typical RAG pipeline involves four key stages. As shown in Figure 1, during the first stage which is the query understanding phase, the user submits a question in natural language, which is interpreted by the system to determine underlying intent. Next comes vector embedding generation, where the query and documents are transformed into their numerical representations, known as embeddings, using various models such as BERT, Sentence Transformers, OpenAI Embeddings, Mistral, or Cohere. Query embeddings are then compared against a documents embedding vector database to retrieve the most relevant documents using similarity search. Popular tools used at this stage include ChromaDB, FAISS, Pinecone, Weaviate, and Milvus. Finally, in the answer generation stage, a text-based large language model, such as GPT, Claude, Gemini or LLaMA, processes the retrieved chunks and synthesizes a coherent and context-aware response for the user.
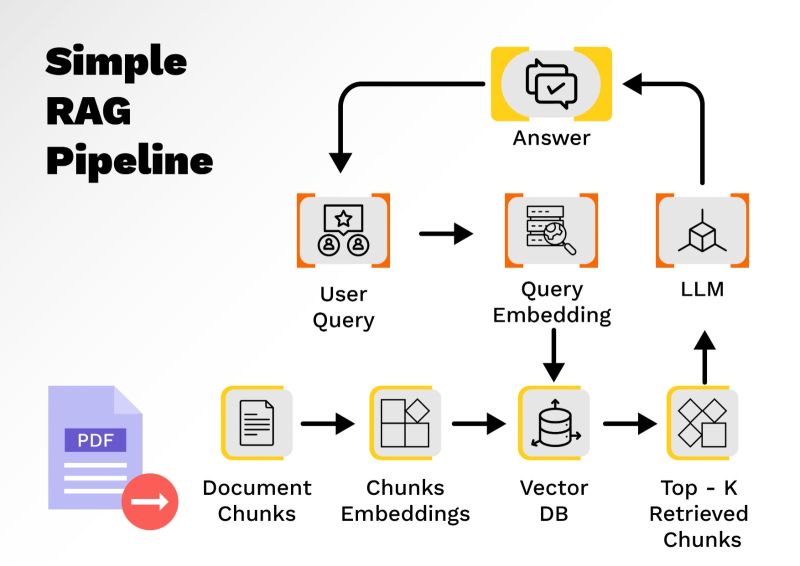
Figure 1: Simple RAG pipeline
To enable this workflow, traditional RAG systems rely on several tools and models. For generating embeddings, models like OpenAI Embeddings, Cohere, and Sentence-BERT are commonly used. For storing and retrieving embeddings efficiently, vector databases such as FAISS, Pinecone, Weaviate, and Milvus are widely adopted. On the generative side, powerful LLMs like GPT-4, Claude 3, Mistral, and LLaMA 3 are often used to create responses. Frameworks such as LangChain and LlamaIndex act as orchestration layers, seamlessly connecting these components and managing the overall pipeline.
The Need for multimodal RAG
Traditional RAG systems focus primarily on text-based data. Despite their effectiveness in handling text-based queries, traditional RAG systems have several limitations. They cannot process non-textual data such as images, tables, videos, or scanned documents. Their capabilities are restricted to semantic search based solely on textual similarity, which makes them unsuitable for analyzing mixed-format documents like PDFs containing tables, diagrams, or charts. This limitation becomes critical in enterprise environments, where data often spans structured, unstructured, and visual content. For instance, a scanned annual report containing revenue tables and product images cannot be effectively understood or summarized using a traditional RAG pipeline. These constraints highlight the need for multimodal RAG systems, which can seamlessly process and integrate insights across multiple data types.
Multimodal RAG: Architecture and Fundamental Understanding
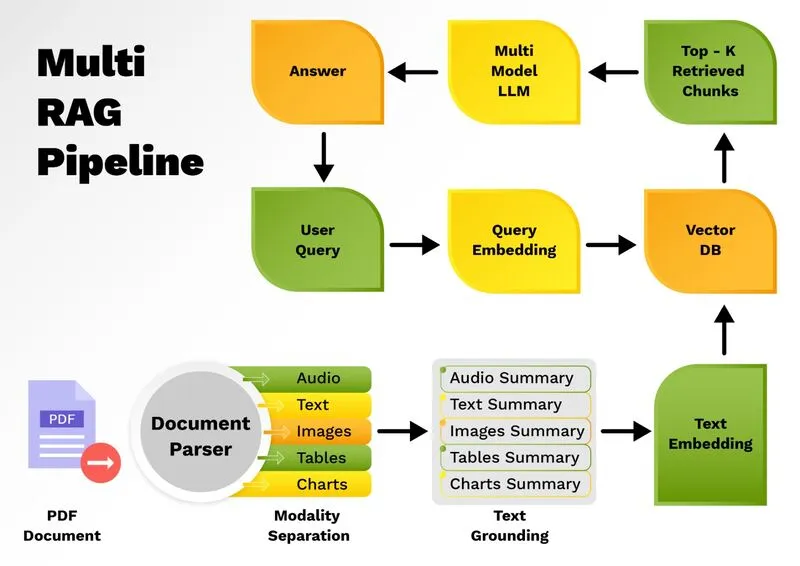
The Multimodal RAG architecture extends the traditional RAG pipeline by enabling retrieval and generation across multiple data modalities, including text, images, and tables. Unlike standard RAG systems, which primarily work with unstructured textual data, multimodal RAG systems must handle content-rich documents such as PDFs, scanned reports, research papers, and multimedia datasets that contain images, structured tables, and textual content. This requires a more sophisticated approach to embedding generation, storage, retrieval, and synthesis.
As shown in Figure 2, the multimodal RAG architecture begins with input ingestion, where documents containing mixed modalities i.e. text, images, audio, video and tables etc. are processed. While text can be directly embedded using models like OpenAI Embeddings, Cohere, or Sentence-BERT, images and tables require a different treatment. Tables are semi-structured and can often be handled as a special form of text, but images pose a unique challenge. To address this, multimodal RAG systems first convert images and tables into concise textual summaries using vision-language models like GPT-4o, BLIP-2, or LLaVA. These generated summaries are then transformed into embedding vectors, ensuring consistency across modalities. This approach allows all forms of data whether originally text, images, audio, video and tables etc. to be represented uniformly within the vector space.
Once embeddings are generated, they are stored in a vector database such as ChromaDB, FAISS, Weaviate, or PostgreSQL with pgvector. However, alongside the vector database, a document store is also maintained, containing the original data in its raw form including high-resolution images, structured tables, and unprocessed text. Each document in the document store is assigned a unique identifier, which maps directly to the corresponding embedding stored in the vector database. This mapping ensures a seamless connection between retrieved embeddings and their original multimodal content.
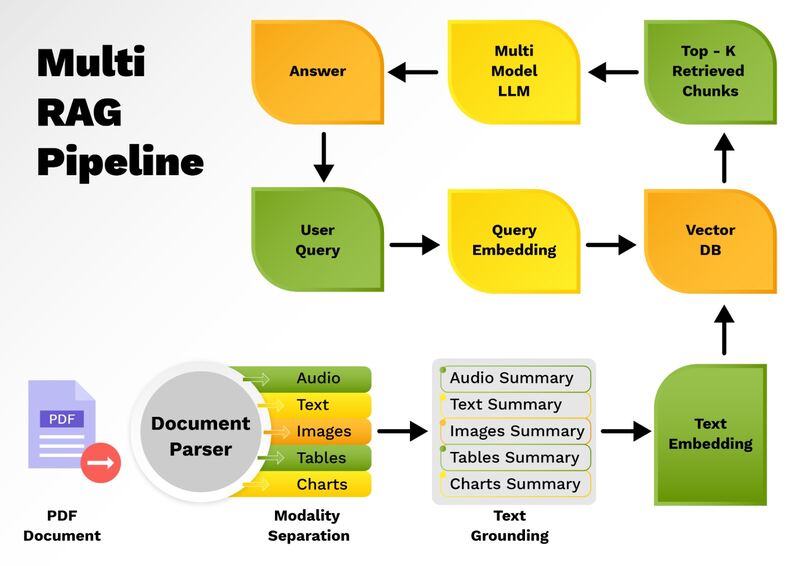
Figure 2: Multimodal RAG pipeline
For the retrieval process, specialized retrievers are used, such as LangChain’s MultiVectorRetriever. This retriever operates on both the vector store and the document store simultaneously. The vector store enables similarity search on embeddings, while the document store provides access to the original content when needed. For example, if the query is related to a revenue figure from a table or a trend shown in an image, the MultiVectorRetriever identifies the relevant embeddings in the vector store, retrieves the associated document ID, and fetches the original content from the document store. This ensures the retrieved information is both highly relevant and multimodally comprehensive.
In this architecture, even text summarization is optional but often recommended. By summarizing textual content along with image captions and table insights, the system maintains uniformity in stored embeddings and achieves more consistent retrieval results. During the answer synthesis stage, a multimodal LLM such as GPT-4o, Gemini 1.5, or Claude 3.5 Sonnet combines retrieved insights from all modalities to generate a single, cohesive response. For example, when a user queries, “Summarize the Q2 financial report with key revenue insights and chart analysis”, the pipeline extracts table summaries using models like TAPAS, generates captions for bar charts via BLIP-2 or GPT-4o, retrieves relevant text sections, and integrates all findings into one unified response.
This architecture makes multimodal RAG pipelines far more powerful and versatile than their traditional counterparts. By converting diverse data types into a common textual representation for embeddings, maintaining a synchronized vector-document storage mechanism, and leveraging multimodal LLMs for synthesis, these systems can efficiently process and reason across complex documents and deliver context-rich, accurate, and insightful responses.
Real world applications of Multimodal RAG
Multimodal RAG is transforming industries by enabling AI systems to process and reason over diverse types of information text, images, tables, audio, videos, and structured data etc. in a unified way. In healthcare, multimodal RAG can integrate radiology images, doctors’ notes, and lab reports to assist in diagnostics and treatment recommendations. For example, a physician could query a patient’s medical history and receive a response that combines insights from MRI scans, pathology images, and textual reports. In the financial sector, analysts can leverage multimodal RAG to process quarterly earnings reports, which often include tables, charts, and textual summaries. By extracting trends from structured tables, generating captions for financial charts, and combining them with narrative insights, businesses can quickly gain actionable intelligence.
In e-commerce, multimodal RAG enables richer search and recommendation systems by combining product descriptions, user reviews, and product images. A customer could, for instance, upload a product image and receive recommendations based on visual similarity, customer sentiment, and technical specifications extracted from textual content. Similarly, in the legal domain, multimodal RAG can assist in reviewing complex contracts and regulatory filings by processing scanned images, annotated PDFs, and structured compliance tables to generate concise legal summaries. Enterprise knowledge management is another major area where multimodal RAG excels, allowing organizations to unify information scattered across reports, documents, databases, and multimedia content into a single intelligent retrieval system. These applications highlight the versatility and impact of multimodal RAG in real-world problem-solving across multiple domains.
The Future of Multimodal RAG
The future of multimodal RAG is deeply connected to the evolution of generative AI and agentic systems. As enterprises generate ever-growing volumes of unstructured, structured, and visual data, the demand for systems capable of comprehensively understanding multiple modalities will continue to rise. Future advancements will likely focus on improving cross-modal reasoning, where AI systems not only retrieve information from different modalities but also establish relationships between them. For instance, financial analysts may soon receive insights that correlate numerical trends in tables, descriptive findings from images, and narrative interpretations from textual reports all in a single response.
We will also see a growing emphasis on domain-specific multimodal models designed for healthcare, finance, legal, and manufacturing sectors, optimized to handle specialized data formats. Integration with real-time data streams is another emerging trend, where multimodal RAG pipelines will be capable of processing live video feeds, IoT sensor data, and real-time documents to provide instant insights. Moreover, multimodal RAG will play a critical role in agentic AI architectures, where autonomous AI agents leverage multimodal retrieval to perform complex tasks, conduct continuous learning, and make data-driven decisions. With innovations in LLMs, embeddings, vector databases, and orchestration frameworks, multimodal RAG systems are poised to become the backbone of next-generation intelligent information systems.
Conclusion
Multimodal RAG represents the next evolution of information retrieval and generation, addressing the limitations of traditional RAG systems by seamlessly integrating textual, visual, and structured data into a unified processing framework. By leveraging multimodal embeddings, advanced retrievers, specialized vector storage, and powerful multimodal LLMs, these systems deliver context-rich, accurate, and insightful responses to complex queries. Whether it is summarizing a PDF containing charts and tables, correlating patient reports with MRI scans, or analyzing product reviews alongside images, multimodal RAG enables organizations to unlock the full potential of their data.
As AI adoption accelerates, the ability to process diverse information sources will be critical for industries seeking to stay competitive. Multimodal RAG provides a scalable and intelligent approach to solving this challenge by bridging the gap between unstructured, structured, and visual knowledge. Its applications span healthcare, finance, e-commerce, legal, and enterprise knowledge management, offering transformative capabilities for decision-making. With ongoing advancements in vision-language models, agentic AI, and real-time multimodal understanding, multimodal RAG is set to become a foundational technology in the future of intelligent, data-driven solutions.